
Hazel is a real-time interactive application and rendering engine created by Studio Cherno and community volunteers. Check out the main website for more information about Hazel.
This site will continue to grow and house the documentation for using Hazel. Check out the Getting Started page for information on how to build and run Hazel.







Getting Access
In order to get access to Hazel source code and make use of the page below you have to make sure you are a Patreon Supporter III or above. This is the best way of supporting the development of Hazel and it's technologies.
Requirements
One of our goals is to make Hazel as easy as possible to build - if you're having any difficulties or weird errors, please let us know. We currently only support building on Windows 10 and Windows 11 with Visual Studio 2022, Visual Studio 2019 is no longer supported. The minimum supported version of Visual Studio 2022 is 17.2.0, Hazel may not compile on versions before that. You also need the following installed:
Here you'll find a list of all the third-party tools and SDKs that you'll need to install in order to build Hazel:
Make sure that you add everything except for the .NET Framework SDK to your PATH environment variable. Most likely the installers will give you the option to so automatically.
Hazel also (experimentally) supports Linux, please see Hazel on Linux for more information.
Building and Running
The following information is for Windows only. For information on getting started with Hazel on Linux -- please see Hazel on Linux
Assuming that's all installed and ready to go, you can proceed with the following:
- Clone the repository:
git clone --recursive https://github.com/StudioCherno/Hazel - Run
Scripts/Setup.bat- this will setup the current repository as your active Hazel installation and generate project files so you can build Hazel - Open
Hazel.sln(in the root of the repository) and build the entire solution in eitherDebugorReleasex64(Build -> Build Solution). You can then run theHazelnutproject which should be your startup project. By default, this will load the Sandbox project found inHazelnut/SandboxProject/Sandbox.hproj
.NET SDK
Hazel makes use of C# as a scripting language, and because of that we also provide a "Hazel-ScriptCore" project, which contains Hazels C# API. This however means that in order to build Hazel you need to have the .NET SDK installed. Hazel makes use of .NET 8.0, and all projects that are made in Hazel also use that specific version.
If you're using Visual Studio to build Hazel you'll have to open the Visual Studio Installer program, and make sure you've selected the ".NET desktop development" workload from the "Workloads" tab, you can find an example of this in the image below.

You may be required to restart your computer after installing the workload.
Vulkan
Hazel requires Vulkan SDK 1.3.204.1 to be installed, and the VULKAN_SDK environment variable set to your installation path. If you do not have the correct version installed, the Setup script should offer to download and install the correct version for you.
The Vulkan SDK installer now offers to download and install shader debug libraries - you must install these libraries if you would like to build Hazel in the Debug configuration. To do so, simply check the (Optional) Debuggable Shader API Libraries - 64 bit option in the Select Components part of the installer, as seen in the image below.

You can also download and install the Vulkan SDK manually if you wish, or if the Setup scripts have failed.
Pulling the latest code
The master branch is required to always be stable, so there should never be any build errors or major faults. Once you've pulled the latest code, remember to run Scripts/Setup.bat again to make sure that any new files or configuration changes will be applied to your local environment.
Supported Platforms
Here you can find a list of the platforms that Hazel currently supports.
If you can't find the platform you're looking for on this page you should assume that Hazel does not currently, and most likely never will, support that platform.
Fully Supported
These are the platforms that Hazel has been tested on, and we've determined that Hazel should run without any serious problems.
If you find an issue relating to any of these platforms please open an issue here: https://github.com/StudioCherno/Hazel/issues
- Windows 10 (64-bit)
- Windows 11 (64-bit)
NOTE: Hazel currently only considers 64-bit Windows versions supported, and it's unlikely that 32-bit support will ever be added
Experimental Support
These are platforms whose support is still in active development. Expect some instability or shortcomings in workflow.
As above, please consider reporting any issues you encounter.
- Linux Based Systems
Unsupported Platforms
These are platforms that Hazel most likely won't work on.
- Windows 7
- MacOS
Supported Editors + Toolchains
Hazel will in theory support any IDE or toolchain that https://premake.github.io/docs/Using-Premake#using-premake-to-generate-project-files supports, however we've only tested the toolchains/IDEs listed below.
- Visual Studio 2022
- CodeLite

NOTE: This tutorial is for an older version of Hazel which may differ from more recent versions!
Welcome to the documentation of making your first game in Hazel! Assuming you have followed the steps in Getting Started you should have a working checkout of Hazel. Here we will learn how to make a very basic endless runner in Hazel similar in some aspects to Alto's Adventure. We will be a ball rolling down a hill avoiding obstacles and "dying" on collision.

Although we said endless, to keep the code a little bit simpler for the sake of this tutorial, we will not make it endless, but far enough for no one to get to the end.
1. Creating a new project
Open to the visual studio solution Hazel.sln, Build the project in Release and press F5 to run and debug the startup project, which will be Hazelnut by default. You should be greeted with the default scene of the Sandbox Project.

Navigate to File -> CreateProject (top left corner)
This should bring up the following popup:

Give your project a name and specify the directory and proceed to create it, take note of the path as we will need it in the next step. Press "Create" and you should be greeted with a brand new project.
2. Setting up command line arguments
Right now we are going to set up command line arguments to make working in this project a little bit easier.
Close Hazelnut, either by navigating to File -> Exit or by simply pressing Alt+F4
-
Navigate to the already open visual studio solution
Hazel.slnand find theHazelnutproject.
-
Select the project and press
Alt+Enterwhich will bring up the project properties -
Navigate to
Configuration Properties -> Debugging, make sure that the configuration is set toAll Configurationsand change the Command Arguments to be the path of the project we just created. IMPORTANT: Make sure to provide the absolute path to the.hprojfile.
Repeat steps 1-3 for the Hazel-Runtime project as well.
3. Navigating in the Editor
Open Hazelnut, by default Hazel will now open our new project.
Before we begin making our game it would be useful for you to know how to navigate in the scene and what some of the panels that we are going to be using are called.
Editor Camera
We navigate in the scene by using the Editor Camera, to move the Camera, you must hold down Right Mouse Button, and then use W,A,S,D to move it Forward, Left, Backward and Right respectively. Use Q and E to simply modify the Y-Translation of the Camera, allowing you to ascend or descend respectively. And holding down Alt paired with the following Mouse Buttons: Left Mouse Button, Right Mouse Button, Middle Mouse Button will activate the Arcball Camera Mode: Orbit, Move, Zoom respectively. Hopefully this short description is enough to provide you with the ability to fly around your scene.
Panels
These are the different panels that will be referred to throughout this tutorial, if you ever can't find them navigate to View and make sure they are active, and if they are still not showing up where they should try clearing your imgui.ini files' docking data.



4. Setting up the scene
Now we are ready to begin creating our game! This tutorial is not meant to be a guide on how to make a Triple-A game or even anything that would be worth being published anywhere but the purpose of this tutorial is to create familiarity with Hazel as a game engine and to familiarize you with the workflow of creating, scripting and building a basic game in Hazel that would use a number of different systems.
-
You should be greeted with a very blank, dark looking scene. Save the scene, by pressing
Ctrl+Sor by navigating toFile -> Save Scene. Call the Scene "Game" -
Set the scene as the startup scene of the project by going to
Edit -> Project Settingsthis will bring up the Project Settings Panel and under General settings you should see aStartup Sceneproperty, click on it to bring up a dropdown menu and select our scene.
-
Right-Clickon the Scene Hierarchy Panel (the panel to the left) -
Create -> Sky Light -
In the Entity Properties window:
You should now be able to see a Sky Light Component
You can either import an Environment Map which is a .hdr image or do what we are going to do and
- Check the Dynamic Sky option and the scene
You can copy our Sky Light Component settings which would give you a dusk-y look

or set it up the however you would like.
5. Creating the Entities necessary for the game
Now we will set up the scene geometry, Camera, materials and all the entities that will be necessary for this game to run.
-
Right-Clickin theScene Hierarchy Panel -> Create -> 3D -> Cube. Set the Cube's transform to this:
-
Right-Clickin theScene Hierarchy Panel -> Create -> 3D -> Sphere. Set the Sphere's transform to this:
Also add a Point Light Component to the Sphere by navigating to
Entity Properties Panel -> Add -> Point Light Componentand change the settings to be the following:
-
Right-Clickin the Scene Hierarchy Panel -> Create -> 3D -> Cone. Set the Cone's transform to this:
We will use the Cube to be our ground, Cones to be our obstacles and Sphere to be our player.
-
Right-Clickin the Scene Hierarchy Panel -> Create -> Camera -> From View Set the camera's transform to be this:
-
Create an empty entity
Right-Clickin theScene Hierarchy Panel -> Create -> Empty Entity, and call it "Spikes". We will use it to be the parent of our spikes later, just to have a slightly cleaner scene. -
Create an empty entity
Right-Clickin theScene Hierarchy Panel -> Create -> Empty Entity, and call it "Scene Controller". We will use this entity to control the scene and the game loop. Add aTextComponent to this Entity by navigating to theEntity Properties Panel -> Add -> Textand keep it at the default settings. -
In the Content Browser Navigate to the Materials Directory and create the following Materials
- Player Material - Albedo Color Code #FF881B and Emission to 4.0
- Ground Material - Albedo Color Code #000000
By this point you should have the following entities in your scene:
- Sphere
- Spikes (Empty Entity)
- Scene Controller (Empty Entity)
- Cone
- Cube
- Camera
- Sky Light
6. Assign the Materials to the Meshes
- In the Scene Hierarchy Panel and select Sphere
- In the Entity Properties Panel, under Static Mesh Component, assign our Player material by either dragging it in or by clicking on the dropdown menu.
- Rename the Sphere to "Player" by pressing
F2with the Scene Hierarchy Panel focused or by navigating to the Entity Properties Panel and clicking on the tag.
Repeat this for the Cone, and the Cube, setting their material to Ground Material and renaming them to "Spike" and "Ground" respectively.
7. Creating a simple Camera follow Script
Whenever you create a new Hazel Project or you add a C# file to an existing Project - it is usually recommended to run Win-CreateScriptProjects.bat located in the root Project Directory.
-
Open the Project's Visual Studio Solution either by navigating to the root directory and opening it or by using the editor and Clicking
Edit -> Open Visual Studio Solution -
Create a New Script by
Right Clicking on the C# Project-> Add -> New Item..., searchEntityin the search bar to the right, you should see a template script calledHazel Entity Script, select it and name itPlayerController.cs`
If you cant see the template when you search for it make sure you install the Hazel Tools extension available in Visual Studio Market Place or use this code here as a starting point instead:
using Hazel;
namespace FirstGameInHazel
{
public class PlayerControllerScript : Entity
{
/// <summary>
/// OnCreate is called once when the Entity that this script is attached to
/// is instantiated in the scene at runtime
/// </summary>
protected override void OnCreate()
{
}
/// <summary>
/// OnUpdate is called once every frame while this script is active in the scene
/// </summary>
protected override void OnUpdate(float deltaTime)
{
}
}
}
Important things to keep in mind:
- In order for the Script to be able to be picked up by the editor, the class accessibility has to be set to
public OnCreate()is called before the first frame,- If you have 30 scripts in the scene the order of execution of those scripts will be random but
OnCreate()for all of them will be called before the first frame. - Frequency of how often
OnUpdate(float ts)is called will be equal to the number of frames your machine can render per second unlessV-Syncis enabled (it is enabled by default). - If
V-Syncis enabled the number of frames is determined by the monitor's refresh rate
In order to create a simple camera follow script we will need only three lines of code, following from the template above
If you're on master then follow the code below:
using Hazel;
namespace FirstGameInHazel
{
public class Camera : Entity
{
private Entity Player;
protected override void OnUpdate(float deltaTime)
{
Player = FindEntityByTag("Player");
if(Player != null)
Translation = new Vector3(Translation.X, Player.Translation.Y + 10.0f, Player.Translation.Z - 0.7f);
}
}
}
And if you're on dev then follow the code below:
using Hazel;
namespace FirstGameInHazel
{
public class Camera : Entity
{
private Entity Player;
protected override void OnCreate()
{
Player = FindEntityByTag("Player");
}
protected override void OnUpdate(float deltaTime)
{
if(Player)
Translation = new Vector3(Translation.X, Player.Translation.Y + 10.0f, Player.Translation.Z - 0.7f);
}
}
}
8. Adding Physics Bodies
Now we will add physics to our game and make the objects capable of collisions with each other! This is really simple to do and all it would require is the addition of the appropriate collider and a Rigid Body. When geometry is created in the way that we created it, Physics Colliders are added by default so all thats left to do is add a Rigid Body to all of them, simply:
-
Select all three entities (Player, Spike and Ground),
-
Navigate to the
Entity Properties Panel -> Add -> Rigid BodyThis will add a Rigid Body to each Entity.
-
Click Player and set it's Rigid Body from
StatictoDynamicsince we want this body to be influenced by Gravity and other Forces.Changing the body type of the Rigid Body will bring up more settings, we want to change a couple:
Under Constraints we want to
- Freeze Position X, since the game that we are making is essentially going to be in 2D.
- Freeze XYZ Rotations.
-
Create a Physics material by going to the
Content Browser Panel -> Materials -> Right-Click -> New -> Physics -> Physics Material -
Double-Clickto open it and change theStatic FrictionProperty to0.1andDynamic FrictionProperty to0.4
-
Assign this material to both the Ground and the Player's Physics Colliders' Material Property

Now if you have followed the steps up until now, you should upon playing your scene see a rolling ball
9. Duplicating the Spike Entity
Parent our spike entity to our Spikes entity, by dragging the former onto the latter in Scene Hierarchy Panel. Having done that select the Spike Entity and press Ctrl + D four times. Now the Spikes entity should be the parent to five Spike Entities, all of which contain a Static Rigid Body and a Collider. All that's left is to position them along our Ground and this step will be done!
10. Create a Player Controller Script
Important things to keep in mind:
- In order for the Script to be able to be picked up by the editor, the class accessibility has to be set to
public OnCreate()is called before the first frame,- If you have 30 scripts in the scene the order of execution of those scripts will be random but
OnCreate()for all of them will be called before the first frame. - Frequency of how often
OnUpdate(float ts)is called will be equal to the number of frames your machine can render per second unlessV-Syncis enabled (it is enabled by default). - If
V-Syncis enabled the number of frames is determined by the monitor's refresh rate
Using the template as a starting point we will now add some basic behavior to the player
using Hazel;
namespace FirstGameInHazel
{
public class PlayerControllerScript : Entity
{
private RigidBodyComponent m_Rb;
private bool m_ShouldJump;
private float m_JumpForce = 16.0f;
protected override void OnCreate()
{
m_Rb = GetComponent<RigidBodyComponent>(); // The rigid body component that's on our player
m_Rb.MaxLinearVelocity = 18.0f; // Setting a maximum velocity so that our player won't endlessly increase their speed.
}
protected override void OnUpdate(float deltaTime)
{
m_Rb.MaxLinearVelocity = Mathf.Clamp(m_Rb.MaxLinearVelocity + 0.01f, 0.0f, 25.0f); // Slowly increasing the players max speed.
if(IsGrounded()) // Only get the jump input if the player is currently on the ground.
{
GetInput();
if(m_ShouldJump) // If space has been pressed this frame - jump
m_Rb.AddForce(new Vector3(0.0f, 1.0f, -25.0f / 90.0f).Normalized() * m_JumpForce, ForceMode.Impulse); // Adding a force to the RB.
}
else
{
m_Rb.AddForce(Vector3.Down * m_JumpForce / 15.0f, ForceMode.Impulse); // if the player has jumped, add a heavier gravity
}
m_ShouldJump = false; // Should jump is only true for one frame because we do not want to apply the force every frame.
}
private void GetInput()
{
if(Input.IsKeyDown(KeyCode.Space))
m_ShouldJump = true;
}
bool IsGrounded()
{
// Raycast(origin, direction, maxDistance, hit)
return Physics.Raycast(Translation + new Vector3(0.0f, -1.0f, 1.0f) * 0.51f, new Vector3(0.0f, -1.0f, 1.0f), 0.01f, out RaycastHit hitInfo);
}
}
}
11. Create Scene Controller Script
Now we will create a Script that will be responsible for making our game run, by moving the obstacles forward, and completing our game loop.
If you're on master then follow the code below:
using Hazel;
namespace FirstGameInHazel
{
public class SceneController : Entity
{
public Entity[] Spikes;
private Entity Player;
private int m_FurthestSpikeIndex;
private float m_AngleOfGround;
private TextComponent m_Tc;
protected override void OnCreate()
{
m_Tc = GetComponent<TextComponent>();
m_FurthestSpikeIndex = 4;
Player = FindEntityByTag("Player");
m_AngleOfGround = FindEntityByTag("Ground").GetComponent<RigidBodyComponent>().Rotation.X;
}
Transform m_PlayerTransform;
protected override void OnUpdate(float deltaTime)
{
Player = FindEntityByTag("Player");
if(Player != null)
{
MoveSpikes();
m_PlayerTransform = Player.Transform.WorldTransform;
}
}
private void MoveSpikes()
{
for(int i = 0; i < Spikes.Length; i++)
{
if (Spikes[i] == null)
continue;
if (Spikes[i].Translation.Z > Player.Translation.Z && Mathf.Abs(Spikes[i].Translation.Z - Player.Translation.Z) > 26.0f)
{
float currentFurthestSpikeZ = Spikes[m_FurthestSpikeIndex].Translation.Z;
float offset = Hazel.Random.Float() * -6.0f - 7.0f;
float newZ = currentFurthestSpikeZ + offset;
float newY = (float)Math.Tan(m_AngleOfGround) * newZ; // Trigonometric way of figuring out the new Y location Tan(theta) = Opp / Adj
m_FurthestSpikeIndex = i;
Spikes[i].Translation = new Vector3(Spikes[i].Translation.X, -newY, newZ);
}
}
}
}
}
And if you're on dev then follow the code below:
using Hazel;
namespace FirstGameInHazel
{
public class SceneController : Entity
{
public Entity[] Spikes;
private Entity Player;
private int m_FurthestSpikeIndex;
private float m_AngleOfGround;
private TextComponent m_Tc;
protected override void OnCreate()
{
m_Tc = GetComponent<TextComponent>();
m_FurthestSpikeIndex = 4;
Player = FindEntityByTag("Player");
m_AngleOfGround = FindEntityByTag("Ground").GetComponent<RigidBodyComponent>().Rotation.X;
}
Transform m_PlayerTransform;
protected override void OnUpdate(float deltaTime)
{
if(Player)
{
MoveSpikes();
m_PlayerTransform = Player.Transform.WorldTransform;
}
}
private void MoveSpikes()
{
for(int i = 0; i < Spikes.Length; i++)
{
if (Spikes[i] == null)
continue;
if (Spikes[i].Translation.Z > Player.Translation.Z && Mathf.Abs(Spikes[i].Translation.Z - Player.Translation.Z) > 26.0f)
{
float currentFurthestSpikeZ = Spikes[m_FurthestSpikeIndex].Translation.Z;
float offset = Hazel.Random.Float() * -6.0f - 7.0f;
float newZ = currentFurthestSpikeZ + offset;
float newY = Mathf.Tan(m_AngleOfGround) * newZ; // Trigonometric way of figuring out the new Y location Tan(theta) = Opp / Adj
m_FurthestSpikeIndex = i;
Spikes[i].Translation = new Vector3(Spikes[i].Translation.X, -newY, newZ);
}
}
}
}
}
As you can see that in the first line of the class, we have a public Entity Array, within Hazelnut we need to expand the count of the array to 5 and place each of our spikes in the array, by dragging it from the Scene Hierarchy Panel into the property reference on the Script. Make sure to drag the furthest spike into the last index of the array as the script behavior depends on that
This script also assumes that the Spikes are already rotated correctly as it won't modify the spikes translation in any way.
At this point you should have an endless runner!
12. Adding Collision Functionality and Finishing the Game Loop
At this point, you have a player that will jump, and roll over the spikes (sometimes), we need to know when the player is colliding in order to kill the player and restart the round.
In order to do that we will set a Collision Callback in the Player Script, this will be the function that gets called the moment we collide with something.
This is quiet simple to do:
Change the OnCreate() function to be the following and add the functions OnCollisionBegin and GameOver()
protected override void OnCreate()
{
m_Rb = GetComponent<RigidBodyComponent>(); // The rigid body component that's on our player
m_Rb.MaxLinearVelocity = 18.0f; // Setting a maximum velocity so that our player won't endlessly increase their speed.
CollisionBeginEvent += OnCollisionBegin; // Setting a collision callback, a function that will run every time we collide with something.
}
private void OnCollisionBegin(Entity other)
{
if(other.Tag == "Spike")
GameOver();
}
private void GameOver()
{
Destroy(this); // Destroying our player.
}
And in the Scene Controller Script we would have to provide a way of restarting the game in the OnUpdate(float deltaTime) function append an else branch to the if statement
protected override void OnUpdate(float deltaTime)
{
...
else // If the player is dead proceed with the game loop.
{
Translation = m_PlayerTransform.Position + Vector3.Up * 5.0f;
Rotation = m_PlayerTransform.Rotation + Vector3.Up * Mathf.PI / 2.0f;
m_Tc.Text = "Game Over\nPress Enter to Play Again!";
if(Input.IsKeyPressed(KeyCode.Enter))
SceneManager.LoadScene("Scenes/Game.hscene");
}
}
So now if our player is no longer valid, because it has been destroyed in our PlayerController script, the Scene Controller Script will present the option to restart the game and will reload the scene upon the pressing of the Enter Key.
13. Creating Prefabs in Hazel
Now we will create a simple death effect by Instantiating some small Spheres on the Player's death. So let's learn how to create prefabs.
-
Navigate to the
Scene Hierarchy Panel ->Right-Click-> Create -> 3D -> Sphere -
Add a Dynamic Rigid Body to the Player
-
Create a New Material and Assign it to the Static Mesh Component, I've set mine to have the Albedo color of
#FF0000but feel free to create your own material. -
When you have finished Editing your entity, Create a new directory in the Content Browser and Name it "Prefabs".
-
Drag the Entity from the Scene Hierarchy Panel into the directory and you should now have a prefab.
If you notice the prefab in the scene will be blue in color, if it is ever red that means that the prefab reference broke, learn how to fix broken prefabs here.
14. Instantiating Prefabs
This is quiet simple to do, just like public Entity will create a publicly settable Entity in Hazelnut, a public Prefab will do the same for prefabs.
So having dragged in our Particle into the field we will be ready to Instantiate them upon death!
So in our player script we need the following changes:
public class PlayerControllerScript : Entity
{
public Prefab Particle;
...
private void GameOver()
{
for(int i = 0; i < 20; i++) // Instantiating some particles.
{
Vector3 scale = Scale * 0.4f * Random.Float(); // Randomizing the scale between Vector3(0.0f) and Vector3(0.4f)
Vector3 translation = Translation + Random.Float() * Vector3.One; // Randomizing translation slightly between Vector3.One and Vector3.Zero
Transform transform = new Transform(translation, Vector3.Zero, scale); // Creating a new Transform
Instantiate(Particle, transform); // Instantiating a prefab with a Transform
}
Destroy(this); // Destroying our player.
}
...
}
This Script will now Instantiate 20 Particles on the Player's death.
15. Keeping Score
Lets provide some visual feedback on how the player is doing, by keeping track of the distance that the player has traveled and displaying it.
-
Add a Child entity to the player and name it TextHolder and add a child to that entity and name it Text. You should have the following Hierarchy:

-
Change the Transform of the Text Holder to this:

-
Add a Text Component to the "Text" Entity, Write some dummy data in there like 10,000. Setting it's transform to this:

-
Now in the Player Controller Script add a
public Entity TextEntityand assign that to be our "Text" Entity in Hazelnut. -
Add scripting behavior to Player Controller Script:
public class PlayerControllerScript : Entity
{
public Prefab Particle;
public Entity TextEntity;
private TextComponent m_Tc;
private RigidBodyComponent m_Rb;
private bool m_ShouldJump;
private float m_JumpForce = 16.0f;
protected override void OnCreate()
{
m_Rb = GetComponent<RigidBodyComponent>(); // The rigid body component that's on our player
m_Rb.MaxLinearVelocity = 18.0f; // Setting a maximum velocity so that our player won't endlessly increase their speed.
m_Tc = TextEntity.GetComponent<TextComponent>(); // Getting the Text Component.
CollisionBeginEvent += OnCollisionBegin; // Setting a collision callback, a function that will run every time we collide with something.
}
...
protected override void OnUpdate(float deltaTime)
{
m_Tc.Text = Mathf.CeilToInt(Mathf.Abs(Translation.Z)).ToString() + " m"; // Setting the player's score, not showing the decimal points;
...
With this we now have a Text displaying the meters we've traveled!
16. Adding Audio
We will now learn the workflow for adding audio in Hazel which is a very necessary part to every game you're going to create!
We will not be creating anything too complicated and just have the following sounds in the game:
- Jump Sound
- Death Sound
- Soundtrack
First things first we need the .wav or .ogg files, .ogg being recommended due to it's smaller size. At the moment Hazel doesn't support .mp3 files.
For sound effects I will use bfxr, and for the Soundtrack I will use this Royalty Free track by Denis Maksimov.
In the Content Browser within the "Audio" directory I prefer to usually make a "Source" directory where I save my .ogg and .wav files.
-
In the "Audio" directory
Right-Click -> Audio -> Sound Config -
Create and name one of these for each Audio file you have, in my case its 3.
-
Double-Clickon each Sound Config and assign the source audio to be the appropriate one.For the Soundtrack Sound Config make sure to check the "Looping" checkbox.

-
Open the Audio Events Editor by navigating to
Edit -> Audio Events -
Create a Play Event for each SoundConfig name it {SoundConfigName}, Adding the Play Action and Setting the correct config;

-
In the Scene Hierarchy Panel add Audio Components to the SceneController and Player Entities.
- In the Player's Audio Component un-check the "Stop When Entity Is Destroyed" checkbox
- Set the SceneController's Start Event in the Audio Component to be the Soundtrack Event and check the "Play on Awake" checkbox

-
Add an Audio Listener Component to the Camera.
With the Camera selected Navigate to
Entity Properties Panel -> Add -> Audio Events Listener -
Build the Sound Bank!
Navigate to -> File -> Build Sound Bank -
Open the Player Controller Script in Visual Studio
public class PlayerControllerScript : Entity
{
public Prefab Particle;
public Entity TextEntity;
private AudioComponent m_Audio;
...
protected override void OnCreate()
{
m_Audio = GetComponent<AudioComponent>();
...
}
private void GameOver()
{
...
m_Audio.SetEvent("Death");
m_Audio.Play();
Destroy(this); // Destroying our player.
}
protected override void OnUpdate(float deltaTime)
{
...
if(IsGrounded()) // Only get the jump input if the player is currently on the ground.
{
GetInput();
if(m_ShouldJump)
{
// If space has been pressed this frame - jump
m_Rb.AddForce(new Vector3(0.0f, 1.0f, -25.0f / 90.0f).Normalized() * m_JumpForce, ForceMode.Impulse);
m_Audio.SetEvent("Jump");
m_Audio.Play();
}
}
...
}
With this the audio should be working! And now we are ready to build our game!
17. Building the Game
See The Runtime and Shipping Your Game

In order to distribute your game as a standalone executable rather than an editor project, Hazel (and every other game engine) has something called a runtime. There is a project called Hazel-Runtime in the root of the repository (accessible in, for example, the Visual Studio solution Hazel.sln) which builds into an executable that will run your project without the editor.
This Hazel Runtime project is what you distribute when you ship your game. As a standalone C++ executable, you have the freedom to customize specific details to suit your distribution needs, from configuring engine systems to adding build information and icons, to adding custom code and dependencies.
To run your project in the runtime, you first need to build it from Hazel's editor. We'll go over how to do this for the included Sandbox project, however this process is basically the same for any project - you just might have to tweak some variables.
Step 1 - Build Your Project
The first step is to build your C# code and project data/assets. Make sure that Coral.Managed, Hazel-ScriptCore, and your C# project (Sandbox in this case) have built successfully. Make sure you can hit the Play button in the editor, and your game plays as expected (this will ensure scripts have been properly built).
Ensure your Startup Scene is set correctly in your Project Settings (Edit->Project Settings) as this will determine the first scene to load when you launch your game.
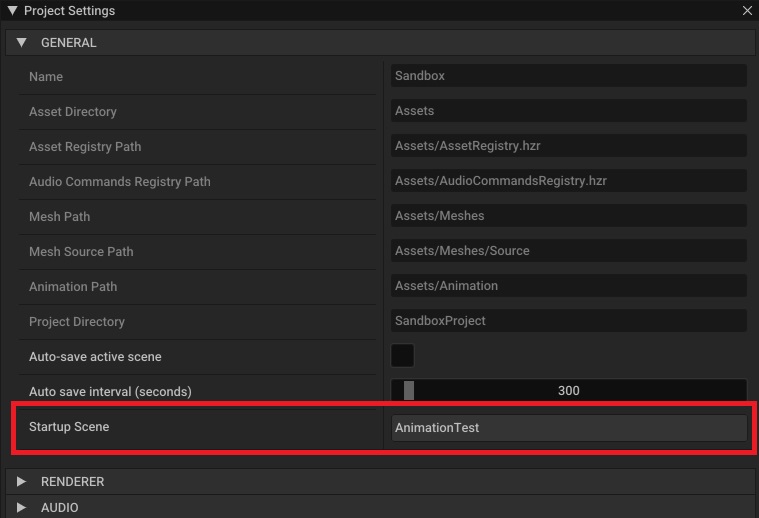
You can then select File->Build All to start a build of all required data and assets into Hazel's runtime formats.
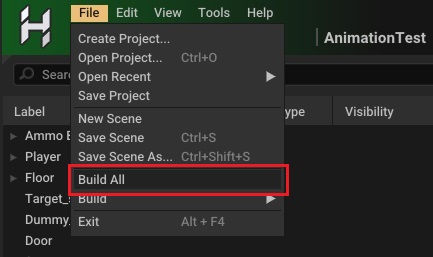
Note that you can also build different types of runtime data separately via the File->Build-> menu, which is useful since building Asset Packs typically takes the longest and may not be required depending on what you've changed during the development.
Step 2 - Configure and Run the Runtime
Once you've built all required data and assets, you can now run your project in the runtime! The following instructions will be for Windows, and will describe running your project through Visual Studio 2022, with a debugger attached in the Release build configuration.
Firstly, make sure your solution configuration is set to Release and the Hazel-Runtime project is set as your startup project (right-click -> Set as Startup Project).
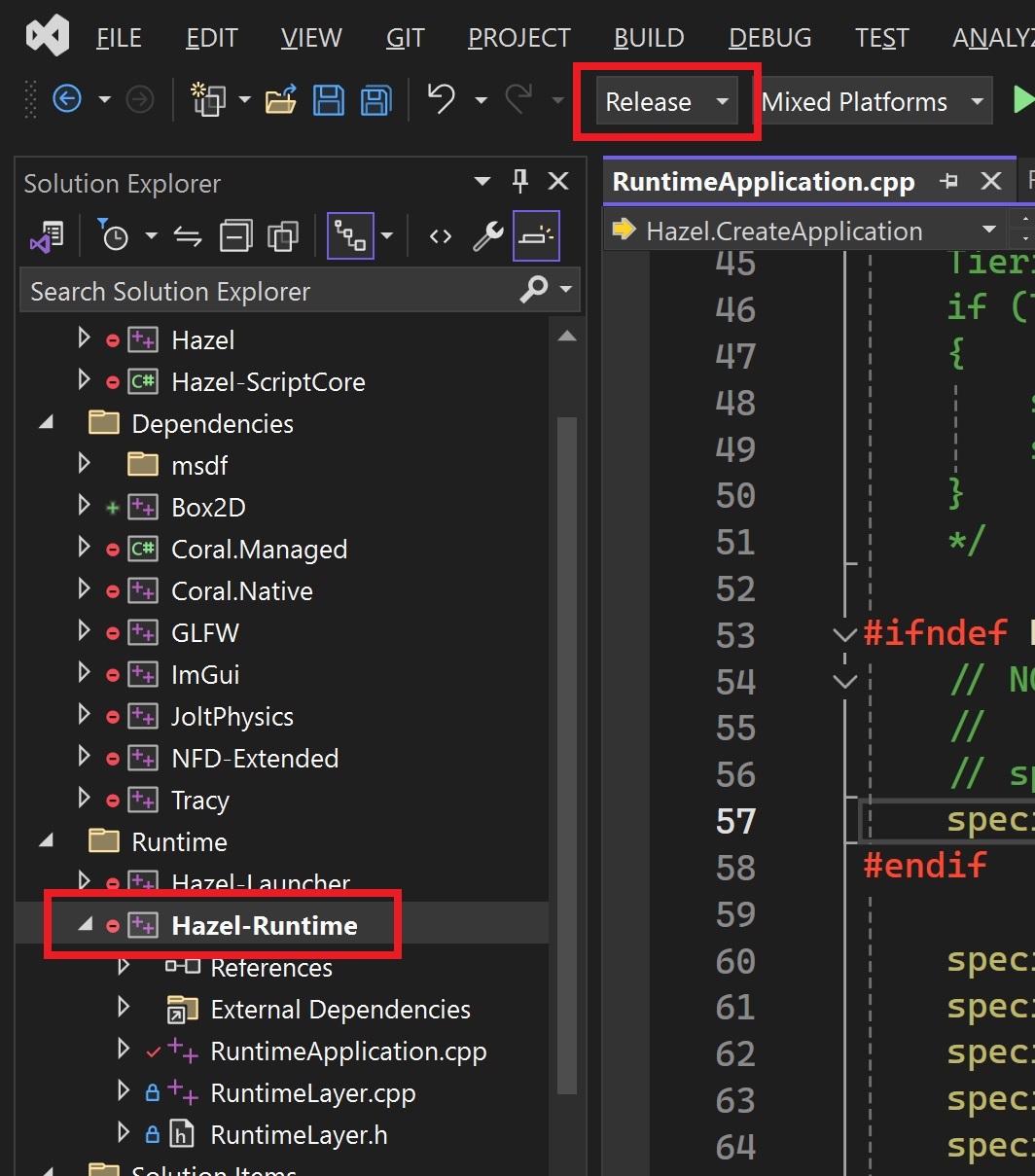
The next step is very important - you need to make sure your working directory is set correctly! In order to run your project with the runtime successfully, Hazel needs to load the files that it needs. This includes the files you've just built, but also some core engine files.
There are two ways to set your working directory when running Hazel Runtime: externally through the application's working directory, or through C++ code in the ApplicationSpecification used to create the Hazel application. Note that the latter will be relative to the former. Below, both ways are described.
Setting your working directory through Visual Studio
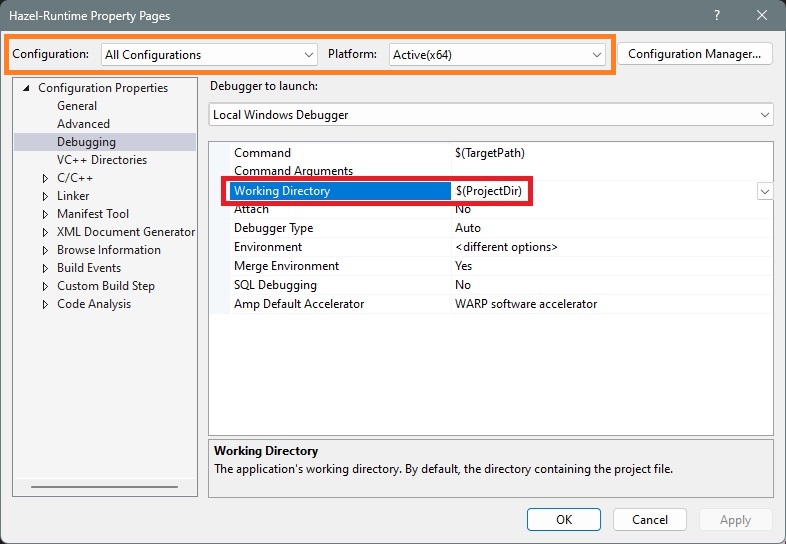
Open Hazel-Runtime's property pages (right-click on Hazel-Runtime in the Solution Explorer and select Properties), and set the Working Directory under the Debugging page as shown below. Make sure that the Configuration and Platform are set to what you want, as shown in orange below.
Setting Hazel Runtime's working directory through code
RuntimeApplication.cpp defines the runtime application's specification. The specification contains a setting for WorkingDirectory, which can be used to set a working directory for Hazel to use. Note that if a relative path is used, this will be relative to the application's original working directory, for example as set in Visual Studio above.
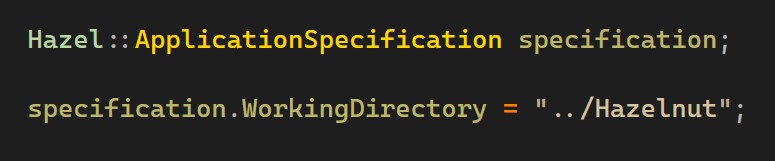
By default, Hazel 2024.1 ships with this WorkingDirectory setting set to "../Hazelnut", as seen above. This is useful during development, because it will use all required core engine resources straight from the repository you are working in, since these resources reside within the Hazelnut directory.
You will almost certainly want to remove or change this setting when creating a build for use outside the Hazel solution in Visual Studio.
Loading Your Project
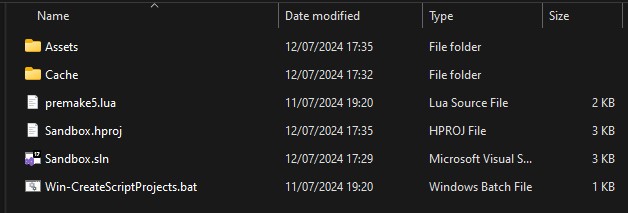
Once your working directory has been correctly set, you need to actually load your project! To do this, you must specify the root directory of your project. This is the directory that contains your Assets directory, and (during development) your .hproj file.
Below is the root directory of the included Sandbox project, which is located in Hazelnut/SandboxProject relative to the root of the Hazel repository.
Setting the project to load can be done by setting the projectPath variable to a relative or absolute path, found in the first line of the Hazel::CreateApplication function in RuntimeApplication.cpp. You can also set this path via a command line argument. See below image.
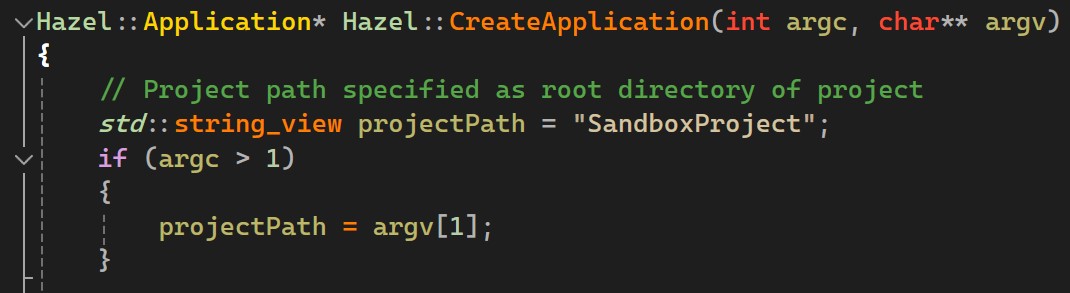
Note that since the Sandbox project is relative to the Hazelnut directory, which has been specified as the working directory by default (as explained above), the project path can simply be set to SandboxProject if that project is to be loaded.
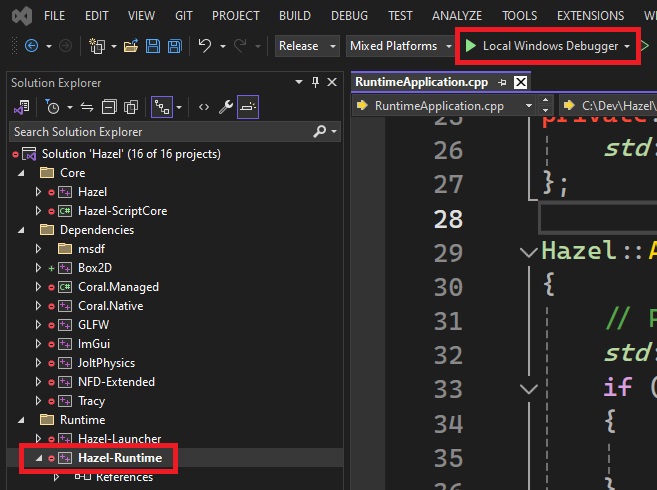
Step 3 - Run the Runtime!
You are now ready to run the runtime! If Hazel-Runtime is set as the startup project, you can press the Local Windows Debugger "play" button (as shown below) or press F5 on your keyboard. You should now be running your project in the runtime!
Release is strongly recommended as it provides a balance of debugging and performance. Debug is often quite slow, but useful for more thorough debugging, and Dist contains no debug information and lots of useful features in Hazel written for debugging during development are stripped.
Building a Distribution Build to Ship Your Project
Coming soon...
Here you will learn the different workflow in order to create within Hazel.

You will know when a prefab is broken when you see it's name and it's type rendered in red in the Scene Hierarchy Panel. It should look like this:

If thats the case then by following the next couple of steps you will be able to fix it no problem!
1. Enable "Advanced Mode"
-
Navigate to
Edit -> Application Settings -> Hazelnut -
Enable "Advance Mode" if it wasn't on already.

2. Find the Prefab in the Asset Manager
-
Navigate to
View -> Asset Manager -
Enable the "Allow Editing" option.
-
Search for your prefab by name. Careful name here means name on disk, i.e. Content Browser, the name in the Scene Hierarchy Panel may not necessarily be the same.
-
Copy the Prefab's Handle.

3. Modifying the root Prefab's ID.
-
Select the entity in the Scene Hierarchy Panel.
-
The topmost Component in the Entity Properties Panel, should be the prefab component.

-
Replace the Prefab ID with the Prefab's Handle that we copied in the last step.
-
Make sure to save the scene so you don't loose your changes.
-
That should fix your broken prefab reference!


This is a page detailing how you can make various assets in order to achieve best compatibility with Hazel. This page will be especially useful when Hazel doesn't yet function as other game engines and will help users quicker learn different workflows in order to make Hazel Compatible assets.
At Studio Cherno we use various tools for asset creation, such as:
- Blender - 3D Modelling / Animating
- Substance Painter - 2D Texturing
- Photoshop - 2D Texturing
Here you will find tutorials, detailing our workflows within those programs.



When animating make sure that all the animation data is on the bone. No object transform data will be seen in Hazel. This example will be making a simple one bone animation, the principle will not change for more bones.
1. Create an armature
Shift + A -> Armature

2. Bones Visibility
Make bones visible with the “in front” property Navigate to Object Data Properties (Stickman Figure) -> Viewport Display -> Check the In Front property

Should you need further help on this step you can find it here.
3. Apply All Transforms
Make sure that you have applied all transforms (CTRL-A in Object Mode) to the bone and the object, preferably parent the bone to the object and animate at World Origin in Blender. In our case since this is a brand new cube and armature there is no offset from World Origin. Failing to do this can result in funky results when importing to Hazel.

4. Parent the mesh
Parent the mesh to the armature, make sure armature is selected last, like in the image below it will have a light orange outline.


5. Weight Painting
Automatic weight painting can often be wrong on models with more bones and geometry. Repainting may need to be done to achieve better results. Blender's tools aren't exactly the best for that at times. In our case of a single bone automatic weight painting works perfectly since the single bone is responsible for 100% of the geometry’s movement.
6. You are ready to start animating!
I like to have my viewport set up the following way in order to be able to visualize actions on one view and the timeline or graph editor on the other.


7. Animate the object
Now it's time to Animate the object by going to Pose Mode (make sure to select the bone otherwise it won’t show up)
a. If you’re finding that the animation doesn’t happen in a linear fashion change the handle type of the keyframes, do this by selecting the entire keyframe (right clicking the topmost track), then Handle type, then Vector.

By default keyframes are circular shapes, there are kite / rhombus shapes which signifies a ‘free’ handle type, that can be edited in the graph view, a vector handle type will be a square keyframe, in the image below the first is a ‘Vector Handle Type’ Keyframe and the second is a ‘Free Handle Type’.

b. By default Blender's animation settings are in Quaternions which for any normal human being would be difficult to understand to change the animation rotation type navigate to the “N” menu. NOTE: The animation will still be using quaternions internally, it will just be more "readable" in Euler angles.

If it’s not visible you can hit “N” on your keyboard or navigate to the “item” section on the side bar. Then simply change the rotation in the dropdown menu from Quaternion to one of the many Euler options. Make sure to do this before starting your animation since these Euler animation tracks would need to be re-added to every single keyframe
c. Multiple different animations on a single mesh can be achieved by creating different actions in Blender, unfortunately sometimes not all actions get exported correctly so where out of three different animations only two will actually make it into Hazel unfortunately this happens quite often. My work around to make sure that this is less likely is by:
-
i. Making sure that Fake User is active on all the actions. That’s the little shield icon near the action name.
-
ii. Deleting redundant actions - this is somewhat tricky to do but this post can help with figuring it out.
-
iii. In the worst case scenario, creating a new Blender file and appending the armature, mesh and all the actions, checking each action individually and then exporting to Hazel. Appending allows you to bring data from one Blender project to another in a very Blender friendly way which is 100% non-damaging of your data in any way.
d. One again make sure none of your animation is an ‘Object transform’ since that movement data will not be visible in Hazel. This can show up in several ways, one if you moved the bone in object mode and two if you animated the mesh instead of the bone, below are screenshots of both those scenarios


Just make sure to delete those tracks if they’re not empty, I prefer to delete them anyway just to make sure I am always animating the bone and not the object.
8. Exporting the animation:
If you have a large scene in blender make sure to export only parts of it that you intend to export. Blender allows you to do this in several ways. I usually use ‘Selected Objects’ under Limit To and make sure to Select all the objects in the Scene Hierarchy Panel. My preferred format for exporting is the glTF Binary (.glb) since it doesn’t create multiple files like the glTF Separate.
NOTE: Hazel doesn't really support glTF Embedded so avoid exporting as that one.
-
Under Transform tab keep the default settings
-
Under Geometry tab keep the default settings
-
Under Animation tab keep the default settings
Save the file to your project directory.
9. Importing to Hazel
Import like a normal mesh by dragging into the scene, but this time make sure that you import as Dynamic Mesh and all the options below are selected as well, the only optional one being Generate Colliders. That one is recommended to be turned off, as there have been problems with it on occasion.

NOTE: Hazel will likely change how it imports assets in the future, so step 9 may look different sometime soon.

Importing Mixamo Animation to Hazel is super simple! This guide will outline what is a very intuitive process anyway!
1. Select the character or upload your own to Mixamo
In this example we will be downloading one of the default characters the Y bot.

2. Downloading skinned mesh + animations
- i. Navigate to the animations tab
- ii. Choose the first animation that you would like
- iii. Download the mesh with the animation and the following settings:

Frames per second can obviously be changed, but its important that under Skin, With Skin is selected.
Repeat steps i to iii for every animation that you would like to import. At the time of this guide being written, Hazel doesn't support Animation only import, with time that should be added but for the time being, every animation needs to be downloaded from mixamo with skin.
3. Importing to Hazel
Open up your project and import the Meshes, starting with your main one. In the future Hazel's workflow with importing assets is likely to change, but at the time of writing this this is the way the import looks like.
These are the settings for the main mesh:

These are the settings for the "animation meshes":

4. Delete unnecessary meshes and entities
You can now delete all the .hmesh files that were created and all the t-posing entities in the scene.
5. Adding animations to the animation controller
All that's left is to add the animation to the animation controller and you're golden!
- i. Open up the Animation controller, you can do this by navigating to
Assets/Animationand finding the relevant.hanimcfile or by selecting the top level entity and double clicking on the assigned field of the Animation Component:

- ii. Greeted with a window that looks somewhat like the window below, press the
Add +button to create an additional state

-
iii. Assign the animation to the new state, by clicking on the
Animationfield. -
iv. Repeat steps ii. and iii. as many times as required to get all you animations into the Animation Controller.
With this, you now know how to import Animation and Rigged Meshes from Mixamo to Hazel, to change the current animation simply adjust the Animation Index in the Animation Component.

Hazel on Linux is currently in an experimental state -- some bugs and instabilities are to be expected. If you experience any problems, please report them to help improve the port for everyone.
The changes to building and workflow are documented below. If not otherwise noted, the port behaves in accordance with Windows builds of Hazel.


While Linux is in an experimental state, it is recommended that users build from the
devbranch of the Hazel repo rather than a release branch; as patches are continuously applied in between releases which may not propogate to the release branch.
Hazel supports both native in-tree builds and Docker builds. The latter is the recommended format for end users not making active changes.
Contents
Docker Builds
1. Setup & Prerequisites
You will need the following tools to get started:
It's recommended that you get these from your system maintainers (e.g. via. a package manager or from user repositories) as they're more likely to be properly configured for your system out of the box.
Docker requires a Docker daemon to be running in order to perform builds and create containers. Information for starting and controlling this daemon can be found here.
Other dependencies will be fetched inside the container during the build process and copied out.
Finally, you should clone Hazel using git clone --recursive -b dev https://github.com/StudioCherno/Hazel. Simply downloading the branch archive from Github or using non-recursive clones will not work -- Hazel handles many dependencies as submodules.
2. Building
The Docker build has been encapsulated in scripts/Docker-Build.sh which invokes docker with the appropriate flags and copies out the resultant binaries (alongside any binaries required from dependencies).
The script does NOT support out of tree builds at present, and attempting to execute it outside of the Hazel root directory will likely create broken orphaned containers.
The script accepts passthrough flags to docker itself; these expose the following variables which can be set via. --build-arg VAR=value:
| Name | Description | Default |
|----------------|-----------------------------------------|---------|
| NPROC | Sets the build parallelism for make | 1 |
| CXXFLAGS | Sets additional C++ compile flags | - |
| BUILD_CONFIG | Sets build mode to Debug or Release | - |
The recommended invocation is:
scripts/Docker-Build.sh --build-arg NPROC=$(nproc) --build-arg CXXFLAGS=-Wno-everything
In order to make use of maximum parallelism and suppress all warnings.
This process is known to take a long time on initial builds. Having adequate parallelism set in the
NPROCvariable mitigates this factor but a fresh clone will still likely take several minutes.
After the script is done -- the Hazel binaries and required dependencies will have been copied out to bin. The Docker build also builds the Sandbox project for convenience, although the ScriptCore .dll is copied out to its appropriate location, so C# project builds can be performed outside of Docker as-usual.
3. Running
Before running Hazel tools from the Docker build -- you must set the following variables from the Hazel root directory:
export HAZEL_DIR=$(realpath .)
export VULKAN_SDK=$(realpath bin/x86_64)
export LD_LIBRARY_PATH=$(realpath bin/)
To run Hazelnut, use:
cd Hazelnut
../bin/Hazelnut [project]
If no project is specified in argv, the Sandbox project will be opened.
Native Builds
This section assumes some familiarity with native toolchains and interaction with GNU Make.
1. Setup & Prerequisites
You will need the following tools to get started:
It's recommended that you get these from your system maintainers (e.g. via. a package manager or from user repositories) as they're more likely to be properly configured for your system out of the box. Toolchains and associated libs/tooling are often provided as a "development" metapackage.
Supported/Tested build toolchain elements are listed below. Please note that this list is not exhaustive, as many aspects of build tooling are entailed as prerequisites to other tools. Additionally,
whilst only glibc is tested at present, we are willing to maintain musl support if issues are submitted; otherwise, alternate C/C++ compilers/standard libraries other than those listed below
will be unlikely to recieve official support.
| Tool | Supported | Recommended |
|----------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------|
| C/C++ Compiler | gccclang | Clang |
| ar Archive Tool | GNU Binutils ar
LLVM llvm-ar | LLVM llvm-ar |
| Linker | GNU Binutils ld
LLVM lld
Mold | Mold |
| C++ Standard Library | GNU libstdc++
LLVM libc++ | - |
The following dependencies will also need to be installed in order to use Hazel:
- The Wayland/X11 packages listed here
gtk3zliblibdwlibunwind- Intel
tbb(Recommend getting "standalone" if downloading from Intel directly) dotnet
You should then clone Hazel using git clone --recursive -b dev https://github.com/StudioCherno/Hazel. Simply downloading the branch archive from Github or using non-recursive clones will not work -- Hazel handles many dependencies as submodules.
When inside the Hazel root directory -- download the VulkanSDK and unpack/rename it such that the SDK root is as follows: Hazel/vendor/VulkanSDK/x86_64.
2. Building
The script build/Linux-Build.sh performs appropriate configure and build steps for native Hazel code, managed Coral/ScriptCore code and the Sandbox project. The build config can be modified by
setting the BUILD_CONFIG variable to Debug or Release. The argv is passed through to the make invocation for Hazel native code -- this should be used to set build parallelism and
toolchain opts. in accordance with regular Makefile practice (CXX, AR and LDLIBS etc.).
The resultant outputs are placed into bin/ in a subdirectory named based on the build config, platform and architecture.
3. Running
Before running Hazel tools -- you must set the following variables from the Hazel root directory:
export HAZEL_DIR=`realpath .`
export VULKAN_SDK=`realpath Hazel/vendor/VulkanSDK/x86_64`
export LD_LIBRARY_PATH="$VULKAN_SDK/lib:$HAZEL_DIR/Hazel/vendor/assimp/bin/linux:$HAZEL_DIR/Hazel/vendor/NvidiaAftermath/lib/x64/linux"
To run Hazelnut, use:
cd Hazelnut
../$BUILD_CONFIG-linux-$(uname -m)/Hazelnut [project]
If no project is specified in argv, the Sandbox project will be opened.
Contents
Building Projects
Hazelnut's built-in functionality for configuring and building projects does not currently work on Linux. Instead, users
must externally use premake to configure their C# project, and dotnet to build it. The template premake5.lua files
should still work appropriately.
When configuring a project, you must ensure HAZEL_DIR is set appropriately to the absolute path of the Hazel root
directory. premake should be set to the vs2022 target in order to generate dotnet-compatible slns. The gmake
backends will not work with .NET Core projects.
To build -- use dotnet build MyProj.sln with any appropriate additional parameters.

New Features 📈
Animation System
Hazel's animation system continues to be improved in 2024.1, with many new features and improvements. There is a roadmap available on the Hazel Milanote board.
Here is an overview of the new features since 2023.1:
- State machine editor and runtime
- Blending animations and state transitions
- Animation events
- Animation asset compression
- Blend spaces (2D blends)
- Additive blends
- "One shot" and "conditional" blends
- IK: Aim (basic)
Scripting Engine
Hazel 2024.1 includes a new C# scripting engine called Coral, which has been open-sourced and can be used in projects other than Hazel.
Coral is a C++/C# wrapper around the .NET CoreCLR library, with the purpose of providing a native interface similar to Mono, but in a more modern style, using .NET Core instead of .NET Framework.
Hazel now requries .NET 8 (see .NET SDK on the Getting Started page).
Async Asset System
Hazel 2024.1 introduces an asynchronous asset system which runs on an asset thread, improving performance and usability. Benefits include:
- Background loading of assets using
AssetManager::GetAssetAsyncwhich improves performance, particularly in Hazelnut - Automatic hot-reloading of assets which have changed on disk, thanks to the asset monitoring system running on the background asset thread
Content Browser Thumbnails
The Content Browser panel now has thumbnails for meshes, textures, materials, and environment maps which greatly improves usability, especially when prototyping. This feature will be expanded in the future to include other asset types, such as prefabs and audio assets.
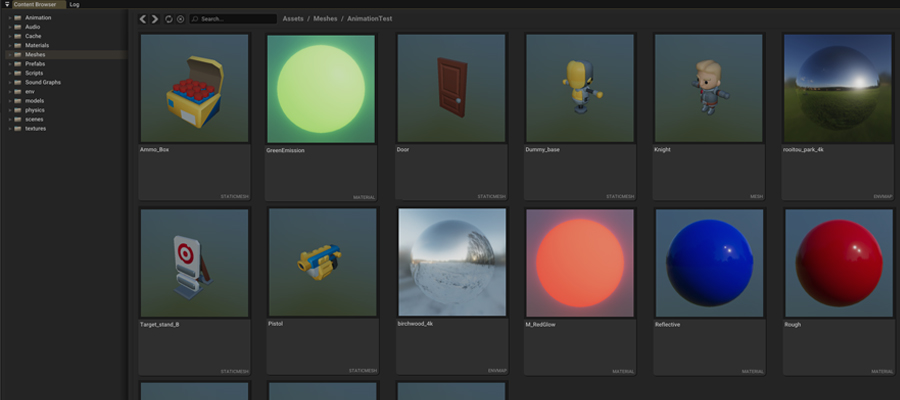
Changes and Bug Fixes 🐞
Packaging and Runtime
- Hazel's packaging system has greatly been simplified and now requires less manual input with the introduction of project data files. See The Runtime and Shipping Your Game page for more details
Assets
- New much more powerful UI for creating meshes, importing animations, etc. from MeshSource
- Reload MeshSource when parent asset is reloaded
- Asset packaging and serialization fixes
Build
- Added Docker support for Linux builds
Core
- Fixed
Hazel::Buffer::Allocatenot setting size to 0 correctly - Editor log messages now also go to stdout
Editor, Projects and Workflow
- Creating a new project will now also create a new scene (called Main) and set this as the startup scene
- New projects now include all core Hazel C# libraries in solution
- Add empty space at the bottom of hierarchy panel so you can easier create new entity
- Make auto-save less annoying - auto-save will now only save if the scene has changed since it was last serialized. This avoids spurious "there is a newer auto-save" nags
- Material editor fixes
Physics
Teleport()method removed from RigidBody component- To "teleport" an entity, you simply set its translation and or rotation. This is the same irrespective of whether the entity has a RigidBody (of any type) or a character controller
- To move an entity via physics (i.e. not teleporting), then use the appropriate method on the physics component (e.g.
RigidBody.AddForce(),RigidBody.MoveKinematic(),CharacterController.Move()or whatever) - Kinematic physics bodies now have their physics world positions synchronized with Hazel world position during the physics simulation.
- CharacterController component has new properties to control whether movement/rotation can be player controlled while the character is in air.
- CharacterController will automatically apply appropriate horizontal "momentum" when character is in air (assuming player control while in air is turned off)
- Added
Rotate()method to CharacterController component (mirroing kinematic body Rotate()). SetRotation(quat)on TransformComponent is now much less likely to produce 180 degree flips in the Euler angle representation of the rotation.- Add RotationQuat property to TransformComponent and a shortcut to it on Entity
- Add Conjugate property to C# Quaternion
- Fixed 2D physics colliders crashing during scene transitions due to being added during deserialization
- Protect engine from user error in use of RigidBodyComponent in game scripts
- When setting entity transforms, corresponding physics bodies must be teleported to world transform + de-duplicate code.
- Improvements to JoltCharacterController
- CharacterController now raises physics events back to gameplay. In other words, Entities with a CharacterController component will now receive physics CollisionBegin, CollisionEnd, TriggerBegin and TriggerEnd events just like RigidBody components.
- refactored the update of character controller components to be more similar to the "CharacterVirtual" sample in Jolt physics repo.
Physics.CastRayandPhysics.OverlapShape(C#) now accounts forRequiredComponentsandExcludedEntities
Rendering
- Textures are now serialized as sRGB(A) for runtime
- Lots of various improvements to mesh importing
- Renderer2D can now optionally render lines "on top"
- Fix hang and eventual crash with Vulkan SDK 1.3.275.0 due to possible incorrect shader reflection array size
- Some Vulkan validation error fixes
- Fixed bloom dirt texture not working
- Improved SkyLight behavior with dynamic sky to fix edge case
- PBR materials imported using assimp now have more robust strategy for extracting data
- PBR shaders changed to read metalness from B channel and roughness from G channel
- Specular IBL fixes
- Fix loading of BRDF LUT
- Regenerate BRDF LUT (means no need to 1-roughness in the shaders)
- Mip level 0 of prefiltered env. map is now a direct copy of the unfiltered env. map (allows for perfectly reflective materials, and also fixes lod level 0 of skybox)
Scenes
- Fixed component add/remove signal handling
- entt on_construct() signals that are relevant only for runtime are now registered only for runtime scene.
- components for which an on_destroy() signal exists must be explicitly removed from entity before entity is destroyed. This gives us control over the order that on_destroy signals are invoked. In particular we want them to happen before the entity's IDComonent and TransformComponent are destroyed.
- Fix runtime instantiation of prefabs with physics
- The ECS has a signal on it so that during runtime, bodies are created in the physics world whenever a RigidBodyComponent is added to an entity (such as happens when a prefab is instantiated)
- This means that the other parts of the entity (in particular the Transform and the Colliders) must be correct before adding the RigidBodyComponent
New Features 📈
- Added Multi-threading to runtime
- Added Asset Packaging
- Added Sound Graphs
- Added
Gizmosupport for multi-entity editing - Added Editor camera in play mode (
ALT+Cfor now) - Added
C#Animation Library - Added
Debug Renderer - Added
SpriteRendererComponent- Added ability to easily create
2D SpritesviaScene Hierarchy Panel
- Added ability to easily create
- Added script creation through
HazelnutHZ-41, HZ-37- Added ability to create
C#scripts from withinHazelnut - You can now open
C#scripts inVisual StudiofromHazelnutbyDOUBLE-CLICKINGon the file in the Content Browser (opens in the firstVisual Studioinstance that you opened) - Creating or deleting a
C#script fromHazelnutnow regenerates theC#project C#Assemblies are no longer built intoAssets/Scripts/Binaries, they're built intoBinariesin the project base directory (although Hazel will still look inAssets/Scripts/Binariesjust in case)
- Added ability to create
- Added the ability to unparent an
EntityviaC#- Setting
Parenttonullwill now cause theEntityto be unparented
- Setting
- Some
RigidBodychanges- Entities with dynamic
RigidBodiesnow store their transform in local space just like all other entities - Added setter for
RigidBodyComponent.BodyType, meaning we can now convertRigidBodiesfromstatictodynamic(and vice versa) during runtime!
- Entities with dynamic
- Re-added equality operators for
EntityandPrefab - Runtime now pre-loads all required assets when loading a scene
- Previously this was done on-demand which caused frame time spikes
- In the future requires a workflow with domains or something
- Reworked the editor console GitLab #200, HZ-63
- Added back Clear on Play button
- Switched filter icons to
Font Awesomeglyphs, they look better and they don't require us to use additional textures - Console is no longer cleared after 500 (499) messages
- Console now automatically scrolls to the latest message
- Automatic scrolling only happens if you're scrolled all the way to the bottom, meaning it can be stopped by scrolling up in the console
- Added Depth of Field
C#bindings forDOFsettings- Added
Show Gizmosin Play Mode - Can also now control
gizmosin play mode if setting is checked - Added
Renderer::CopyImage - Added
ImageUsage::HostRead - Added Transfer
booltoImageSpecificationfor transfer ops ValueWrapper/FieldStoragefixes (needs more fixing)
- Added Spot Lights
- Only one shadow casting spot light for now
- Added proper soft shadow support for spot lights
- Added discard to
Renderer2D.glslshader for better transparency
- Changed
TransformComponentto store rotation as quaternion- Import of assets where a sub-mesh is rotated around
Y-Axisby an exact multiple of90 degrees - Distortion of animated assets if bones are similarly
Gimbal-Locked - Rotating via
ImGuizmono longer forces rotation into range-180to180. - Activating
ImGuizmoover a anEntitywith gimbal locked rotation is now less likely to inadvertently change the transform. - No small drift due numerical precision issues in matrix operations.
- Import of assets where a sub-mesh is rotated around
SHIFT-CLICKin viewport now selects "root"EntitySHIFT-CLICKINGtheleft mouse buttonin the viewport will now select the clicked-on objects top-levelEntity. This is useful when the object you've clicked on is a small part of a dynamic mesh:SHIFT-CLICKwill now select the whole object, which makes it easy to move that object around orCTRL-Dduplicate it.RIGHT-CTRL, andSHIFTkeys now affect selection also (used to be onlyLEFT-CTRL,LEFT-SHIFT)- If an
Entityis selected, then any meshes in child entities are also submitted to the renderer as "selected" (this gives you the orange outline in the viewport around theEntityand all of its children, so you can see much clearer exactly what will be moved around if you were to change selected entities transform etc.)
C# Entitiescan now be compared using==and!=- Added
DOUBLE CLICKINGon an asset field in a component now opens that asset in the relevant editor / window - Some multi-entity gizmo changes
- Rotation gizmo is now rendered correctly when rotating multiple entities at once
- Disabled scaling gizmo when editing multiple entities due to severe bug. Scaling via the properties panel still works
- Added
AudioEventsManagerclass to process and dispatch Audio Events - Material Tables now use
AssetHandlesinstead ofRef<MaterialAsset> - Added a way to set entities' transforms to the Editor Camera's transform + alternate ways to create cameras in scene
Changes ♻️
Core 
- Changed default
ScriptModulePathtoAssets/Scripts/Binaries - Changed
Hazel::Timerinternally to use microseconds instead of nanoseconds for HUGE performance gains - Reworked how
Content Browseritems being "opened" is handled- The new method of handling
Content Browseritem activation is now more inline with other item actions - The new method allows other areas of the engine to handle item activation, so
EditorLayernow handles when a scene asset is double clicked, by opening it in the viewport - This new method will also allow e.g script files to be opened in
Visual StudiobyDOUBLE CLICKINGon it in the future (planning on adding that soon)
- The new method of handling
- Improved
Convex Mesh Collider Cooking- It's no longer possible to set a zero-area triangle threshold of 0 (will be capped at 0.01)
- If we fail to cook a convex submesh because a zero-area triangle was detected we will attempt to cook it again without checking for zero-area triangles, since it's more of an optimization. We may want to change this so that we still check for zero-area triangles but set the threshold really low
- Improved failed cooking log messages
PhysicsLayerManagerno longer allows having multiple layers with the same name- Added virtual functions to
AssetEditorPanelto optionally pushImGuistyle to window - Added a guard to
AudioCommandsRegistryshutdown to prevent overwriting file with empty registry - The open state of panels is now serialized between sessions
Box Collider 2DandCircle Collider 2Dnow takes offset into account- Hazel now builds the script core if it's not already built on launch
Hazelnut
- Disabled the mesh viewer GitLab #138, HZ-163
- Disabled grid by default when scene is playing HZ-50
- Changed the mesh importer to take the correct value for roughness
- Creating a new
Entityin a parent will now position the child at the parents origin - Added (Static)
MeshComponent::Visible - Added support for public
C#strings again Prefabinternal workflow fixes and improvements HZ-58, HZ-56, HZ-55, HZ-52SceneHierarchyPanelwill now no longer silently removePrefab componentsfrom entities when asset handle is invalid- Instead will display
Entitytext in red, retainingPrefab component - Added
"Advanced Mode"toHazelnutto support additional UI that normally shouldn't be visible - This includes viewing the
PrefabComponentin Properties panel for Entity - Changed
UI::PropertyInputforuint64_tto have default step value of0, meaning steps will not be displayed
- Shaders are now included in the
Hazelnutproject - When loading a scene, if there is a newer auto-save then prompt to load that one instead
- Added shortcut for directory creation in the Content Browser
CTRL + SHIFT + NHZ-49 - Added Content Browser Icons
- Added Component Icons
- Removed shortcut for scene creation previously
CTRL + N
Audio 🎧
- Added
ALT + CLICKto remove connections from a node pin - Now only one connection can be connected to any given node input
- Proper sorting of nodes before save/compile
Scripting 📜
- Added settable controller axis deadzones
- Extended controller button polling to include events like
Held/Pressed/Released - Extended mouse button polling to include events like
Held/Pressed/Released C#Assemblies are no longer considered assets- Script Engine is now directly notified when
C#assemblies are modified - Restored code that initializes runtime duplicated entities and
Prefabs(now checked every frame) - Private fields are now considered "hidden"
Projects 🧰
- Newly created projects will now have the default meshes HZ-30
- Replaced default meshes from
FBXtoGLTF - Recent project paths are now verified, and if they are not valid they will be removed
Bug Fixes 🐞
- Fixed beginning second property grid in script components when there are no fields in the script to render
- Fixed Content Browser Item being stuck in rename when its added from outside of the editor
- Fixed Editor Console messages not being cleared when switching projects HZ-199
- Fixed meshes with invalid mesh sources attempting to be packaged into the asset pack
- Fixed clearing materials not working for multiple entities
- Fixed an unnamed entity having an empty string as a display name.
- Fixed weird behavior where importing meshes would create memory-only copies of mesh materials
- Fixed sound graph sources not being released when finished
- Fixed clicking outside the "Build Asset Pack" popup closing it fully
- Fixed "Build Asset Pack" popup not closing automatically when done HZ-195
- Fixed Rotation gizmo being rendered incorrectly when rotating multiple entities at once
- Fixed crash where starting an asset pack build while another one is happening would crash the engine
- Fixed runtime not having a asset pack path by default HZ-194
- Fixed Skybox being rendered incorrectly when SkyLightComponent is present but not set to anything HZ-135 HZ-198
- Fixed long filenames exceeding thumbnail in content browser HZ-191
- Fixed the issue when Audio Commands Registry being overwritten by loading a different project HZ-152
- Fixed scripting issue - Hazel now builds the projects
C#DLLwhen loading the project if it hasn't been built yet HZ-158 - Fixed wrong amount of materials being displayed on mesh changes HZ-85
- Fixed "Open Visual Studio Solution" always opening the solution for the first project loaded HZ-192
- Fixed unsafe access to
s_Controllersmap - Fixed crash when loading mesh with an embedded texture HZ-173
- Fixed crash when instantiating a prefab via
C#and then destroying it within the same frame HZ-181 - Fixed not being able to delete items in the Content Browser without the mouse HZ-83
- Fixed Sound Config changes not updating loaded Sound Config assets. HZ-166
- Fixed
AddComponentPopup showing on the primary monitor ifHazelnutis open on the secondary monitor HZ-49 - Fixed items not being deselected if navigated out through the breadcrumb
- Fixed lights being positioned incorrectly in play mode while parented to a physics body HZ-180
- Fixed crash on simulation stop where a 2D
RigidBodyis present HZ-179 - Fixed
2D Collidersbeing displayed only in editor scene. - Fixed "Show Physics Colliders" for selected
Entityonly working onPhysXcolliders HZ-157 - Fixed skybox getting distorted when the camera is far away from the origin of the world HZ-175
- Fixed new scenes always having the name "UntitledScene" HZ-170
- Fixed incorrectly displayed bounding boxes HZ-174
- Fixed
C#assembly not being reloaded consistently HZ-158 - Removed stack trace from
GetComponentwhen no component is found - Fixed
VulkanSDKnot being able to be downloaded throughSetup.bat - Fixed asset renaming being very bugged HZ-45, HZ-150, HZ-155
- Fixed crash when a
FixedJointComponentwithout a connectedEntityset is in the scene HZ-168 - Fixed items being activated if an item was double clicked whilst renaming HZ-167
- Fixed pre-loading of audio sources and added preview for sound configs with audio file sources.
- Fixed Arcball camera not working when mouse would navigate outside of the viewport HZ-138
- Fixed crash when removing a script component while playing HZ-165
- Fixed
Hazelnutnot updating when deleting files from outside the editor HZ-161 - Fixed bug with dragging a scene to the "Default Scene" field HZ-78
- Fixed crash when showing bounding boxes while having entities with no mesh assigned
- Fixed renaming bug when creating new folders HZ-45, HZ-150, HZ-155
- Fixed crash caused by not clearing file system watcher callbacks when unloading a project
- Fixed asset creation issue for duplicate default names HZ-149
- Fixed issue with selecting a folder immediately after creating it HZ-150
- Fixed crash when opening Audio Events editor in a new project HZ-145
- Fixed old
C#classes showing up in asset dropdown menu after they've been renamed - Fixed crash when using the
RIGHT-CLICK"Duplicate" option in the Content Browser - Fixed scene name not being displayed properly (was always "UntitledScene") HZ-137
- Fixed crash when calling
Physics.Raycast2DfromC#HZ-133 - Fixed Editor Console not being thread safe
- Fixed runtime arrays not functioning for
C#classes (only worked for e.gint,float, etc...) - Fixed a crash caused by destroying runtime entities that had scripts
- Fixed
RigidBodiesnot having correct translation when instantiated usingInstantiateChildHZ-179 - Fixed wrong label for
BoxColliderComponentHalfSize - Fixed crash when caching
C#structs - Fixed
Soundgraphdefault values not working GitLab #204 - Fixed setting reference type values in
C#arrays from C++ - Fixed
Entity.As<>()returningnullptrif the script instance hasn't been instantiated - Fixed Script components serialized with
ModuleNamenot deserializing properly - Fixed jankyness with loading
C# DLLs(we now properly support loading from both Assets/Scripts/Binaries as well as ProjectDirectory/Binaries) - Fixed arrays not being set in the
C#runtime - Fixed runtime length getter crashing for
nullarrays - Fixed string fields crashing the runtime (due to data being interpreted incorrectly)
- Scripting engine now differentiates between script entities and instances of scripts (in terms of storage at least)
- Reloading now works + arrays no longer have to be handled separately
- Fixed
Prefabsnot working with script components - Fixed issue where reader for audio files is not created if the file is not in Sound Bank
- Fixed
RIGHT-CLICKINGdeselecting everything in the Content Browser - Fixed crash when deleting a child
Entityalong with its parent - Fixed
AudioCommandsRegistrylifetime not being tied to Project lifetime GitLab #199 - Fixed Closing sound graph editor after adding a new graph property crashes
HazelnutGitLab #202 - Fixed new project not appearing in Recent Projects
- Fixed zero duration animations not being ignored when importing
DCC - Fixed renaming a sound graph property causing it to lose its value GitLab #201
- Fixed
Scripting->ShowHiddenFieldsnot being deserialized - Fixed major issue in ImGuiUtilities where string format would not match data type
- Fixed
Prefabupdating crash HZ-58, HZ-56 - Fixed
AssetManagernot correctly generating unique names past (01) - Fixed
PhysXcrash on runtime shutdown - Fixed bug with deserializing physics layer
IDs - Fixed actor lock flags being cast to the wrong type
- Fixed not being able to deselect using
CTRLin Content Browser - Fixed possible
PhysX Debuggerleak - Fixed spotlight shadows
- Fixed
AudioCommandsRegistrybeingShutdowntwice onApplicationshutdown - Fixed parameter not being applied if it is the only parameter of the sound graph
- Fixed hash still working incorrectly with substring
string_view - Fixed
Identifiertaking whole data pointed to bystring_view - Fixed delete popup to no longer be triggered by pressing Delete while renaming HZ-59
- Fixed a crash that could happen while renaming and pressing escape
- Fixed crash when attempting to post invalid trigger GitLab #197
- Fixed Links connected to orphan nodes are compiling and crashing. GitLab #198
- Fixed reading wave source issue
- Fixed audio registry not being shutdown on project change
- Fixed recursive including between
ImGui.handImGuiWidgets.h - Fixed crash caused by referencing Materials from
C# - Fixed entities being able to be deleted if the viewport or scene hierarchy wasn't focused
- Fixed not being able to deselect entities using
CTRL + CLICKafterSHIFTselecting - Fixed incorrect mixed values for transform components
- Fixed node link not drawing when "Create New Node" popup activates
- Fixed issue with quick dragging link from a pin
- Fixed crash caused by having
C#arrays withnullvalues in them - Fixed issue with
C#``Entitycaching - Fixed
C#exceptions causing engine to crash GitLab #196 - Fixed
Entitynot being saved when having astatic RigidBodyGitLab #194 - Fixed
Hazel Toolsextension not catching exceptions properly - Fixed crash that would happen when we try to make an array field hidden
- Fixed
SHIFTselecting not working inScene Hierarchy Panel - Fixed old rotation API being used for Spot Lights post-merge
- Fix
CTRL-Dsometimes not duplicating things - Fix scripts not working for
Prefabsinstantiated during runtime - Fixed radius not being passed into Physics.SphereCast
- Fixed some issues with scripting
- Fixed issue where Hazel would consider a field both public and private at times
- Fixed crash caused by attempting to call a constructor on a struct
- Fixed crash when converting a
MonoArraytostd::vector
- Fix crash when trying to set value of a script field of type
bool - Fixed some Editor Panel issues / code styles
- Removed redundant
if (!isOpen)checks from editor panels - Wrapped all editor panels ImGui code inside
ImGui::Beginscope - Also cleaned up
ImGui::Beginif statements to ensure thatImGui::Endis called even if begin returns false (this is how theImGuiexamples does it)
- Removed redundant
- Fixed crash that would happen when duplicating an
Entitywith aScriptComponentthat also has children - Fixed crash that would happen when instantiating a
Prefabor duplicating anEntitythat has an invalid script attached - Fixed minor issue where the scene name would not be copied in
Scene::CopyTo - Fixed a crash that would happen when getting a
nullC#fields value - Fixed constructor calling to always call the parameterless constructor
- Fixed incorrect types passed to
ValueWrapperinScriptUtils::GetDefaultValueForType - Fixed crash when clearing a
C#class in aScriptComponent - Fixed
ValueWrappers buffer getting corrupted on a copy-assignment (would occur if it tried to do a copy assignment on itself) - Fixed crash when trying to get collider debug mesh if it doesn't exist
- Fixed children not being displayed when parent is searched for in scene hierarchy panel
- Fixed Create New Project crash GitLab #191
- Fix multi-select in scene hierarchy not working
- Fixed crash where project would try and load non-existent scene
- Fixed
Hazel-ScriptCorebeing built into wrong directory - Removed option for reloading
C#assembly on play - Fixed Hazel displaying the wrong link GitLab #190
- Fixed some scripting related issues
- Hazel can now automatically reload
C#DLLson build again - Hazel now detects if an asset has the wrong asset type specified in the AssetRegistry file (and automatically corrects it)
- Fixed
AssetType::ScriptModulebeing serialized asScript - Some slight refactoring in
ScriptEngineto get reloading to work properly again + clean up some code - Fixed incorrect
C#PDB type set in premake files C#DLLsnow appear in the Content Browser (we may want to prevent this in the future)
- Hazel can now automatically reload
- Fixed
NormalandMetalnessmaps no being able to be cleared GitLab #189 - Fix crash when importing animation asset with missing tracks
- Fix rendering of dynamic meshes that have mix of animated and non-animated sub-meshes
- Fix crash when dragging mesh asset into scene
- Fix an issue caused by merge of scripting branch
- Fixed issue with default value in
FieldStorage - Fixed crash when iterating over script entities on runtime shutdown
- Fixed
C#arrays not working properly withHazelnut - Fixed crash when trying to get a debug mesh collider without having cooked the collider mesh
- Fixed
C#ValueTypesbeing boxed when setting fromHazelnut - Fixed naming of script internal calls for
SetParameter - Fixed audio issues with surround audio endpoint devices
- Fixed crash related to rendering audio node for failed to initialize sound source.
- Fixed clean up failing to initialize sources and objects
- Fix crashes on
Hazelnutexit HZ-147

Here you will find documentation on Hazel's internal systems, how they work and how to extend them as you might need them.
One of the goals of Hazel and it's developers is to make a versatile tool that is accessible and extendable to how a user might see it fit, in order to accomplish this we adhere to certain coding standards, to ensure that the code is readable and understandable to the user.

This document is for Hazel engineers working on the engine.
Etiquette
The following rules apply to all engineers working on the engine codebase. The motivation behind these is to support a positive collaborative environment, assist in producing a higher quality product for developers and end-users, and keep the code itself as high quality as possible.
1. Code Ownership
Being a Game Engine, Hazel naturally divides itself into many various discrete systems which also need to work together well. Typically, these various systems will have owners - engineers who are responsible for a particular system or section of code, who are usually (but not always) the original authors. There may also be some overlap or multiple owners for certain systems. Usually ownership is implicit upon an engineer writing code; that is to say that an engineer automatically becomes the owner of code that they write (especially true for systems they've designed and implemented). There can always be exceptions to this of course, which falls onto the responsibility of the project's technical directors.
As the name implies, owners are responsible for code which they own. Whenever engineers need to stray into code territory that they do not own, and determine that this foreign code needs to be modified, it's important that certain processes are followed. These processes can be summarized by just a few points:
- Do not modify any code that you do not own unless there is an important reason to (eg. you need to extend a system to accept new input from a feature you're working on). Needlessly changing code is a problem because whenever anything changes, there could be undesirable side-effects which you couldn't possibly even envision - because you didn't write the code!
- If you've determined that you do in fact have a good reason to change code, contact the owner and state your intentions. This is important because the owner responsible for the code will know more about it (and all of its implications, "load-bearing" properties, etc.) than you, and this collaboration can ensure that what you're doing is correct and minimizes any possible negative effects from your changes. It's also just polite to give the owner a heads up, because after all it is their code that you're coming in and changing.
- If there is an emergency - there is a critical bug in the engine that you can fix ASAP even though you don't own the code, contact your Technical Director and inform them of this change.
Just to be clear - you can change code that you own without needing to notify anyone, and ultimately for whatever reason. The burden of responsibility falls on you in that case, because after all you are the owner of the code you're modifying.
2. Self-Documenting Code
One of Hazel's major engineering goals is to promote easy-to-read, good, clean code. This is a very subjective description, however the idea is that your code should be as readable as possible, even to "junior" engineers. Of course there are areas that simply cannot be simplified, or by doing so would affect the engine negatively, but in all areas this idea of clear, simple, and self-documenting code should be followed. This is more thoroughly explained in the Code Style section with specific examples, and includes things like naming symbols descriptively, preferring verbose descriptive code to auto-generated templates or functional style programming which produces more abstract engineer-facing code that can be harder to understand and see the full extent of computation taking place.
Your code should ideally be able to read like an English book as much as possible. If you can make your function make more sense by expanding variable names or adding extra comments - do that!
Code Style
By now Hazel shouldn't really need a Code Style guide, because there is enough existing code in the codebase to answer every stylistic question you might have. Long story short - if you don't know what style to write your code in, look around! There's plenty of code, and your goal is to blend in. Nevertheless, I will try and officially summarize the main points here.
Naming
Classes, functions, member functions, enums, namespaces, source code file names, and most other "titles" are always in Pascal Case (like the Win32 API and Microsoft's C# code style).
Local variables (including parameters) are always camel case. Private member variables are prefixed with m_ and then start with a capital letter (eg. m_VariableName). Static variables (either in a translation unit or class) are prefixed with an s_ and also start with a capital letter (eg. s_StaticVariable).
Here is an example which demonstrates all of these points:
namespace MyNamespace {
static int s_StaticInt = 0;
static void MyFunction();
class ExampleClass
{
public:
void ThisIsMyFunction(int inputVariable)
{
m_MemberVariable = inputVariable;
std::string localVariable = std::to_string(inputVariable);
}
private:
int m_MemberVariable = 0;
};
}
To be continued...

NOTE: This article won't be too useful for anyone who isn't actively developing Hazel, but you can still learn a lot about how the asset system works
Adding custom assets can be a complex task, this guide will show a simple overview of integrating any custom asset with the existing Asset System in such a way that it will accessible from the Content Browser in Hazelnut.

Assets in Hazel are reference counted, and should always be wrapped in a Ref instance. Meaning you should pretty much never allocate an Asset on the stack, since Hazel uses intrusive reference counting, meaning the reference count is stored in the asset instance, not in the Ref instance.
In order to retrieve an Asset you have to request it from the AssetManager class.
Example 1
...
Ref<PhysicsMaterial> material = AssetManager::GetAsset<PhysicsMaterial>(assetID);
...
Example 2
It's also possible to get an asset by the file path (relative to the projects "Assets" directory).
AssetHandle assetID = AssetManager::GetAssetHandleFromFilePath("Physics/PlayerMaterial.hpm");
Ref<PhysicsMaterial> material = AssetManager::GetAsset<PhysicsMaterial>(assetID);
// OR
Ref<PhysicsMaterial> material = AssetManager::GetAsset<PhysicsMaterial>("Physics/PlayerMaterial.hpm");
NOTE: Referencing Assets by ID is the preferred method
Creating New Assets
Most of the time you won't need to create assets programmatically, but Hazel does support doing so.
Ref<PhysicsMaterial> newMaterial = AssetManager::CreateNewAsset<PhysicsMaterial>("MyMaterial.hpm", "Physics/", ...);
The first two parameters are filename and directoryPath. After the first two parameters you can pass a variable number of parameters that will be used to construct the Asset instance.
Ref<SomeTextAsset> asset = AssetManager::CreateNewAsset<SomeTextAsset>("MyTextFile.txt", "Docs/", "This string will be passed to SomeTextAsset's constructor!");
Converting Your Data Structure To Be An Asset
The Data Structure
In order to make your data structure (class or struct) compatible with the Asset System, it must extend the Asset class.
For this example we will be writing a simplified version of the PhysicsMaterial class:
struct PhysicsMaterial : public Asset
{
float StaticFriction;
float DynamicFriction;
float Bounciness;
PhysicsMaterial() = default;
PhysicsMaterial(float staticFriction, float dynamicFriction, float bounciness);
};
The Asset Type
Inheriting from the Asset class isn't enough though. The Asset System needs a way to identify any asset, which is why we need to expand the AssetType enum.
The enum currently looks like this:
enum class AssetType : uint16_t
{
None = 0,
Scene = 1,
MeshAsset = 2,
Mesh = 3,
Material = 4,
Texture = 5,
EnvMap = 6,
Audio = 7
};
We will go ahead and add a value called PhysicsMat, and assign it to a value of 8.
enum class AssetType : uint16_t
{
None = 0,
Scene = 1,
MeshAsset = 2,
Mesh = 3,
Material = 4,
Texture = 5,
EnvMap = 6,
Audio = 7,
PhysicsMat = 8
};
NOTE: You shouldn't change the value of the already existing enum values. Just add yours to the end, and give it the next available value!
We also need to modify these two functions in order for our asset to be tracked properly:
inline AssetType AssetTypeFromString(const std::string& assetType)
{
if (assetType == "None") return AssetType::None;
if (assetType == "Scene") return AssetType::Scene;
if (assetType == "MeshAsset") return AssetType::MeshAsset;
if (assetType == "Mesh") return AssetType::Mesh;
if (assetType == "Material") return AssetType::Material;
if (assetType == "Texture") return AssetType::Texture;
if (assetType == "EnvMap") return AssetType::EnvMap;
if (assetType == "Audio") return AssetType::Audio;
HZ_CORE_ASSERT(false, "Unknown Asset Type");
return AssetType::None;
}
inline const char* AssetTypeToString(AssetType assetType)
{
switch (assetType)
{
case AssetType::None: return "None";
case AssetType::Scene: return "Scene";
case AssetType::MeshAsset: return "MeshAsset";
case AssetType::Mesh: return "Mesh";
case AssetType::Material: return "Material";
case AssetType::Texture: return "Texture";
case AssetType::EnvMap: return "EnvMap";
case AssetType::Audio: return "Audio";
}
HZ_CORE_ASSERT(false, "Unknown Asset Type");
return "None";
}
We need to ensure that our enum value can be properly converted from and to a string.
inline AssetType AssetTypeFromString(const std::string& assetType)
{
if (assetType == "None") return AssetType::None;
if (assetType == "Scene") return AssetType::Scene;
if (assetType == "MeshAsset") return AssetType::MeshAsset;
if (assetType == "Mesh") return AssetType::Mesh;
if (assetType == "Material") return AssetType::Material;
if (assetType == "Texture") return AssetType::Texture;
if (assetType == "EnvMap") return AssetType::EnvMap;
if (assetType == "Audio") return AssetType::Audio;
if (assetType == "PhysicsMat") return AssetType::PhysicsMat;
HZ_CORE_ASSERT(false, "Unknown Asset Type");
return AssetType::None;
}
inline const char* AssetTypeToString(AssetType assetType)
{
switch (assetType)
{
case AssetType::None: return "None";
case AssetType::Scene: return "Scene";
case AssetType::MeshAsset: return "MeshAsset";
case AssetType::Mesh: return "Mesh";
case AssetType::Material: return "Material";
case AssetType::Texture: return "Texture";
case AssetType::EnvMap: return "EnvMap";
case AssetType::Audio: return "Audio";
case AssetType::PhysicsMat: return "PhysicsMat";
}
HZ_CORE_ASSERT(false, "Unknown Asset Type");
return "None";
}
Our asset class will also need to override the GetAssetType() method from Asset, and it will need to provide a static method called GetStaticType().
NOTE: Your Asset won't work if you don't provide these methods! If you don't provide GetStaticType() the code may not even compile!
struct PhysicsMaterial : public Asset
{
float StaticFriction;
float DynamicFriction;
float Bounciness;
PhysicsMaterial(float staticFriction, float dynamicFriction, float bounciness);
static AssetType GetStaticType() { return AssetType::PhysicsMat; }
virtual AssetType GetAssetType() const override { return GetStaticType(); }
};
This is required by certain templated methods in the Asset System.
If you want to associate your asset with a specific file type, you need to modify the s_AssetExtensionMap map in Hazel/Asset/AssetExtensions.h.
In theory this is all the code necessary in order to have the Asset System recognize your asset.
This isn't enough to have the Asset Manager import your asset correctly however. In order to have that functionality we need to implement an AssetSerializer.
Importing/Exporting The Asset
Writing the Serializer
In order to allow the Asset System to import the asset correctly we need to provide a class that the it can interface with.
This is done by creating a class that inherits from the AssetSerializer class.
The AssetSerializer class contains two pure virtual methods.
virtual void Serialize(const AssetMetadata& metadata, const Ref<Asset>& asset) const = 0;
virtual bool TryLoadData(const AssetMetadata& metadata, Ref<Asset>& asset) const = 0;
AssetSerializer::Serialize is called when the Asset System requires an asset to be saved to disk.
AssetSerializer::TryLoadData is called when an asset that hasn't been imported yet is requested by the engine.
Let's go ahead and implement those methods in a class called PhysicsMaterialSerializer.
NOTE: Hazel serializes data using YAML for certain assets. This isn't always the case though.
class PhysicsMaterialSerializer : public AssetSerializer
{
public:
virtual void Serialize(const AssetMetadata& metadata, const Ref<Asset>& asset) const override
{
// We can call .As<>() on a Ref instance in order to cast it to a different type
Ref<PhysicsMaterial> material = asset.As<PhysicsMaterial>();
YAML::Emitter out;
out << YAML::BeginMap;
out << YAML::Key << "StaticFriction" << material->StaticFriction;
out << YAML::Key << "DynamicFriction" << material->DynamicFriction;
out << YAML::Key << "Bounciness" << material->Bounciness;
out << YAML::EndMap;
// It's important that you use AssetManager::GetFileSystemPath(metadata) here since metadata.FilePath isn't in the correct format
std::ofstream fout(AssetManager::GetFileSystemPath(metadata.FilePath));
fout << out.c_str();
}
virtual bool TryLoadData(const AssetMetadata& metadata, Ref<Asset>& asset) const override
{
// Load the YAML file from disk
// It's important that you use AssetManager::GetFileSystemPath(metadata) here since metadata.FilePath isn't in the correct format
std::ifstream stream(AssetManager::GetFileSystemPath(metadata));
if (!stream.is_open())
return false; // We couldn't load the file for some reason, signal the Asset System that we failed
std::stringstream strStream;
strStream << stream.rdbuf();
YAML::Node data = YAML::Load(strStream.str());
float staticFriction = data["StaticFriction"].as<float>();
float dynamicFriction = data["DynamicFriction"].as<float>();
float bounciness = data["Bounciness"].as<float>();
// In order to create a RefCounted object we need to call Ref<Type>::Create(Args)
asset = Ref<PhysicsMaterial>::Create(staticFriction, dynamicFriction, bounciness);
// Here we assign the asset id to this instance of the asset
asset->Handle = metadata.Handle;
// We successfully loaded the asset
return true;
}
};
It's worth noting that the way you load the asset data heavily depends on the type of asset you're implementing. Here's an example of how Hazel loads Textures:
bool TextureSerializer::TryLoadData(const AssetMetadata& metadata, Ref<Asset>& asset) const
{
asset = Texture2D::Create(AssetManager::GetFileSystemPathString(metadata));
asset->Handle = metadata.Handle;
bool result = asset.As<Texture2D>()->Loaded();
if (!result)
asset->SetFlag(AssetFlag::Invalid, true);
return result;
}
Registering the Serializer
Now that we've written the serializer implementation, we need to register it to our AssetType value, so that the Asset Manager can understand that our serializer is meant to be use with our new asset type.
In order to do this we must modify the AssetImporter::Init() method in Hazel/Asset/AssetImporter.cpp. That method currently looks like this:
void AssetImporter::Init()
{
s_Serializers[AssetType::Texture] = CreateScope<TextureSerializer>();
s_Serializers[AssetType::MeshAsset] = CreateScope<MeshAssetSerializer>();
s_Serializers[AssetType::Mesh] = CreateScope<MeshSerializer>();
s_Serializers[AssetType::EnvMap] = CreateScope<EnvironmentSerializer>();
}
As you can see we call CreateScope<T> with the serializer we want to register as the template argument, and store it in a map that has an AssetType as a key.
This allows the Asset Manager to query the map for a given AssetType and get the serializer for that type back.
We need to add our new serializer to this map, making sure to have our own AssetType as the key.
void AssetImporter::Init()
{
s_Serializers[AssetType::Texture] = CreateScope<TextureSerializer>();
s_Serializers[AssetType::MeshAsset] = CreateScope<MeshAssetSerializer>();
s_Serializers[AssetType::Mesh] = CreateScope<MeshSerializer>();
s_Serializers[AssetType::EnvMap] = CreateScope<EnvironmentSerializer>();
// Associate our serializer with our AssetType
s_Serializers[AssetType::PhysicsMat] = CreateScope<PhysicsMaterialSerializer>();
}
And that should be all you need to do in order to integrate your asset with the Asset Manager! This will also ensure that the ContentBrowserPanel deals with your asset properly!

NOTE: This article won't be too useful for anyone who isn't actively developing Hazel, but you can still learn a lot about how the asset system works
Adding custom assets can be a complex task, this guide will show a simple overview of integrating any custom asset with the existing Asset System in such a way that it will accessible from the Content Browser in Hazelnut.


Note
This is marked as "new" to keep the previous workflow docs around until they age out of release.
Overview
Files in Hazel/src/Hazel/Script/ScriptGlue are treated as sources for script
glue code generation. They are compiled as-usual but to ensure interop
functions are correctly selected for generation they need to be in the
Hazel::InternalCalls namespace.
These are processed into both the script glue binding code -- i.e. assigning
function pointers into the managed InternalCalls delegates, and initial
generation of those delegates themselves. This nominally means that the only
requirement to add a new script-accessible function is to write it into a
source file in this folder with a compatible prototype.
There is some special type handling which can be found in the generation script
at scripts/Hazel-ScriptGen.py -- which translates integral types and Coral
types. Other typenames are treated as-is and directly copied into the C#
declaration.
Prerequisites
The clang compiler from the LLVM project must be installed, and a matching
version of the Python clang package
alongside it.
On Windows under VC workflows LLVM can be installed either from
the LLVM project releases page
under LLVM-{version}-win64.exe or via. the Visual Studio installer as the
"C++ Clang Compiler For Windows" workload.
Workflow
- New function that you want exposed to managed code is added to a source file
in
Hazel/src/Hazel/Script/ScriptGlue. The function name must be in theHazel::InternalCallsnamespace to be discovered. Note that all functions which match these criteria will be consumed; helpers should either be placed into an outerHazelnamespace or intoScriptGlue.h/cpp.
namespace Hazel::InternalCalls {
// Would be exposed in managed code as
// `InternalCalls.MyNewThing_NewFunction`
void MyNewThing_NewFunction(int someParameter) {
...
}
}
- Run
scripts/ScriptGen.pyfrom the Hazel root directory to generate the C++ side interface.
python3 scripts/ScriptGen.py -t cxx -C Hazel/src/Hazel/Script/ScriptGlue -o Hazel/src/Hazel/Script/ScriptGenOutput.cpp -l Hazel-ScriptGen/Source/Template.cpp -s {{CLANG SYSTEM PATH}}
Where {{CLANG SYSTEM PATH}} is replaced with the path to standard include
files from your installation -- some example locations would be:
| Installation Type | Path |
|---|---|
| Visual Studio 2022 | C:\Program Files\Microsoft Visual Studio\2022\Professional\VC\Tools\Llvm\lib\clang\19\include |
| Sysroot Install | /usr/lib/clang/19/include |
If no path is provided the script will attempt to deduce the install location
- Run
scripts/ScriptGen.pyfrom the Hazel root directory to generate the C# side interface:
python3 scripts/ScriptGen.py -t cs -C Hazel/src/Hazel/Script/ScriptGlue -o Hazel-ScriptCore/Source/Hazel/Core/ScriptGenOutput.cs -l Hazel-ScriptGen/Source/Template.cs -s {{CLANG SYSTEM PATH}}
- You should ideally expose the function in a nicer manner than the raw interop call -- a structure such as this is typical for wrapping internal behaviour from managed code:
namespace Hazel
{
public static class MyNewThing
{
public static void NewFunction(int someParameter)
{
unsafe { return InternalCalls.MyNewThing_NewFunction(someParameter); }
}
}
}
- When committing changes, ensure that you do include the generated
Hazel/src/Hazel/Script/ScriptGenOutput.cppandHazel-ScriptCore/Source/Hazel/Core/ScriptGenOutput.cs.
Hazel-ScriptCore Folder Structure
All the C# source files belong in Hazel-ScriptCore/Source, no core .cs files should ever exist outside this folder.
Attributes/
This folder isn't too useful for extending just the C# API, it's more useful if you want to extend the Hazelnut Editor. But in short this folder should contain any custom C# attributes that we want to add.
Audio/
Contains all the Audio data / utility classes, but NOT the AudioComponent
Core/
This folder contains some useful core classes, e.g Application.cs, Input.cs and Log.cs. These classes are usually implemented as static for simplicity and ease-of-use.
This folder also contains one of the most important files you'll need for extending the C# API: InternalCalls.cs. Which is the file that contains all methods that we need to implement in C++.
Math/
Contains all the math classes, you'll rarely need to add new files to this folder, but you may want to add methods to the classes that are already defined in those files.
Mathf.cs is where you'd put general math utility methods like Abs, Min, Max, Lerp etc...
Physics/
Contains all Physics data and utility classes / structs, it's the folder where all the collider data classes are defined, it also contains the static Physics class that contains useful physics related methods like Raycast, Overlap methods, etc...
Renderer/
This folder contains all the renderer / graphics related classes like Mesh, StaticMesh, and Material, usually you won't have to extend these classes in any way.
Scene/
This is the main folder that you'll be interested in if you want to extend the core C# API, it contains the Components.cs, Entity.cs and Scene.cs.
The Components.cs file is where you'll modify existing components, and add new components when you want to expose them from C++. I'll provide an example later on that shows roughly how to expose or extend components.
The Entity.cs file contains the Hazel Entity class, which all (or most) game scripts will be sub classed from, you'll very rarely have to modify this file, but if you have to keep in mind that most of the modifications you want to make can probably be done through a component instead.
And please try not to break backwards compatibility when you change this file, we want to avoid breaking game scripts as much as possible.
The Scene.cs will most likely not be used by game scripts directly too much, it contains methods related to interacting with the scene, spawning prefabs, creating and destroying entities, finding entities by ID or by name. Most game scripts will be interacting with the equivalent methods in Entity.cs instead of interacting with the Scene class directly.
Adding Internal Calls (Interop with C# and C++)
You should only add an internal call if you want C# code to call some function in C++, you might want this if you want the added performance of C++, or because you need to interface with, or expose a C++ API to C#.
I'll start by providing guidelines for adding internal calls, please make sure that you follow these guidelines, they're here to make it far easier for others to understand and maintain code that you write, and for the sake of consistency.
Guidelines for writing internal calls in C#
When you add the internal calls to the C# API here are some things you need to consider:
- Internal methods should always be defined inside the
InternalCalls.csfile. Never in the classes that use these methods. - Internal methods should always be defined inside of a
#regionblock to keep the file organized. You can take a look at how other regions are written. - Internal methods should always be named in this format:
ClassName_FunctionName, e.gTransformComponent_GetTranslation, orMeshComponent_GetMaterial. - Internal methods should always be defined as
internal static delegate* unmanaged - Internal methods should always have the same name in C++ as in C#, so a method called
TransformComponent_GetTranslationshould also be called that in C++. - If you need to pass
boolorobjectto an internal call they should be passed asCoral.Bool32andCoral.NativeInstance<object>. - Internal calls follow
Funcstyle syntax for declaring parameters and return types, e.ginternal static delegate* unmanaged<int, int, Coral.Bool32>will take two integers and return aCoral.Bool32.
These are some of the basic things you need to keep in mind, feel free to let me know if you think these guidelines should be updated!
Guidelines for writing internal calls in C++
When you add the internal calls to the C++ API these are some things you need to keep in mind:
- The C++ implementation of an internal call should always be declared in the
ScriptGlue.hfile, and defined inScripGlue.cpp. - In order to register the internal call with the C++ API you have to add this line:
HZ_ADD_INTERNAL_CALL(ClassName_FunctionName);toScriptGlue::RegisterInternalCalls, preferably in the same order that it's declared inInternalCalls.cs. - If an internal method as to log a message it should preferably log these messages to the Hazelnut console, e.g using
HZ_CONSOLE_LOG_INFO. This isn't required though and mainly depends on what you're logging. - Always add internal calls inside the
InternalCallsnamespace in C++. This is required in order to register the function
There's understandably a lot more to keep in mind, but the key point is to follow these guidelines, and to make sure the code you add is consistent with the code that's already in the C++ and C# API.
Example
Here's a very basic example of how to add an internal call to the scripting API, we'll start with declaring the internal call in C#:
Imagine we have a custom struct in C#, and we want to populate that struct with some data from C++, and have our internal call return true if it succeeds. Here's what struct might look like:
// You have to add this attribute to structs that you want to pass to C++
[StructLayout(LayoutKind.Sequential)]
public struct MyCustomData
{
public float MyFloat;
public int SomeInt;
}
// InternalCalls.cs
...
#region MyCustomComponent
internal static delegate* unmanaged<ulong, MyCustomData*, Coral.Bool32> MyCustomComponent_GetCustomStruct;
#endregion
...
Here you can see we define the internal call, it returns a bool, and takes in two parameters, the ulong parameter is just for consistency here, all C# components have to pass the entity's ID to C++ so the engine can know what entity the component belongs to.
And it also takes a pointer to our custom struct, this means that we expect C++ to write some data into this struct, but it can also read from it.
That's really all you need to do in order to define the method in C#. Then in C++ we'll add this code:
// MyCustomData struct (can be a class in C++ but use struct where possible)
struct MyCustomData
{
float MyFloat;
int SomeInt;
};
// ScriptGlue.h
namespace InternalCalls {
...
#pragma region MyCustomComponent
Coral::Bool32 MyCustomComponent_GetCustomStruct(uint64_t entityID, OutParam<MyCustomData> outData);
#pragma endregion
...
}
and then in ScriptGlue.cpp we add the implementation of this function:
// ScriptGlue.cpp
namespace InternalCalls {
...
#pragma region MyCustomComponent
Coral::Bool32 MyCustomComponent_GetCustomStruct(uint64_t entityID, OutParam<MyCustomData> outData)
{
// NOTE: Dummy code, look at the existing internal calls for reference
if (!is_entity_valid)
{
// Log some error here
return false;
}
if (!entity_has_MyCustomComponent)
{
// Should almost never happen but log error if it does
return false;
}
*outData = myCustomComponent.MyData;
// OR:
outData->MyFloat = someFloatValue;
outData->SomeInt = someIntValue;
return true;
}
#pragma endregion
...
}
This just covers the basics of adding internal calls, but it should give you an idea as to how it's done.
Also keep in mind that your C++ and C# struct need to have the exact same memory layout, including things like padding. This can involve manually adding padding to your C# struct.
This page will tell you all the necessary steps you'll need to follow in order to expose a component from C++ to C#.Here are the outline of the step you'll need to complete to expose a component to C#:
- Add
HZ_REGISTER_MANAGED_COMPONENT(MyCustomComponent);toScriptGlue::RegisterComponentTypes. - Implement the C# component by defining a class in
Components.csand make it inherit fromComponent. - Add the necessary internal calls to let the C# component interact with the C++ component and engine systems.
Please try to keep the HZ_REGISTER_MANAGED_COMPONENT in the same order as the the components internal calls, so if your internal calls are defined underneath e.g the RigidBodyComponent in ScriptGlue.h you should register your component and internal calls underneath the RigidBodyComponent in ScriptGlue::RegisterComponentTypes and ScriptGlue::RegisterInternalCalls. This helps keep the files organized.
The way you write a C# component highly depends on the component, but the basics are this:
- You need to add a class to
Components.csthat inherits fromComponent, like this:public class MyComponent : Component. - You need to add methods or properties that calls the necessary internal methods. (Refer to the previous page for info on how to do this)
- Any internal method that needs to interface with your component has to take in the ID of the entity, you can access the ID from within the component by accessing
Entity.ID. - Entity IDs are 64-bit unsigned integers, the C# type for that is called
ulong, and the C++ type is calleduint64_t.
Quick Note on Heap Allocations in C#
One thing that has been a problem in the Hazel script core since the start are heap allocations when calling internal methods. I won't go too deep into heap allocations as a concept, but in C# when you create a new instance of a class by calling new MyClass(), that will result in that object being allocated on the heap.
In Hazels script core we've often been returning a new instance of a class after calling an internal method, here's a quick example from the MeshColliderComponent:
// This is not great because every time we call `MeshColliderComponent.ColliderMesh`
// we allocate a brand new `Mesh` instance every time even if the mesh hasn't changed internally.
public Mesh ColliderMesh
{
get
{
unsafe
{
AssetHandle meshHandle;
InternalCalls.MeshColliderComponent_GetColliderMesh(Entity.ID, &meshHandle);
return new Mesh(meshHandle);
}
}
}
// This is the better way of implementing this property:
// First we add a private member called m_ColliderMesh.
private Mesh m_ColliderMesh = null;
// Secondly we add an AssetHandle property called ColliderMeshHandle,
// this is what actually get's the handle of the Mesh
public AssetHandle ColliderMeshHandle
{
get
{
unsafe
{
AssetHandle colliderHandle;
if (!InternalCalls.MeshColliderComponent_GetColliderMesh(Entity.ID, &colliderHandle))
{
return AssetHandle.Invalid;
}
return colliderHandle;
}
}
}
// Lastly we add a method that will return the Mesh.
public Mesh GetColliderMesh()
{
// Here we make sure that the mesh handle that's stored internally is still valid
// and return null if it isn't
if (!ColliderMeshHandle.IsValid())
return null;
// Here we check if we either haven't set m_ColliderMesh or if the internal
// mesh has changed, if so we create a new Mesh instance
if (m_ColliderMesh == null || m_ColliderMesh.Handle != ColliderMeshHandle)
m_ColliderMesh = new Mesh(ColliderMeshHandle);
// Otherwise we just return the cached version of the Mesh instance
return m_ColliderMesh;
}
I will say that this likely doesn't improve performance, in fact it might have slightly more overhead (it's still not noticeable), but this does reduce the number of heap allocations.
So why do we want to avoid heap allocations? Well for one they can cause performance issues if you allocate objects on the heap every frame, but it would also cause the C# Garbage Collector to run more often. I won't go into a deep explanation as to what the Garbage Collector is or why it's useful, the important part is that it cleans up unused C# objects, and doing so can cause a significant frame drop. So we want to prevent the Garbage Collector from running as much as possible, it will eventually run regardless so it's impossible to completely prevent it from running, and we don't want to prevent it, but we want to delay it.
Caching objects in C# isn't always the best thing to do, you don't really need to cache primitive types unless you really want to, and structs are usually allocated on the stack (although they can be allocated on the heap sometimes) so they're not as necessary to cache.
Properties or Methods?
Should you use properties or methods for interacting with the C++ side of things? Well, it depends. I'd say if you're doing caching that would result in similar code as the example above you should probably use a method, not a property.
I won't go into too much detail on this since it's more a question of good C# code rather than Hazel specific code.